
AI Ticketing Automation Solutions: Getting the Data Layer Right
IT teams are deploying AI ticketing tools at a rapid pace. Research from TeamDynamix indicates AI can deflect between 30 and 60 percent of incoming tickets and cut resolution time by 40 to 90 percent.
The gap between that promise and the results most IT operations teams see traces back to one variable: the quality of the configuration data the AI uses to make routing decisions. When that data is stale, AI ticketing automation creates new problems instead of solving old ones.
What is AI ticketing automation in ITSM?
AI ticketing automation uses machine learning and natural language processing to classify, route, prioritize, and resolve IT service management tickets without manual intervention. In IT operations, effective AI ticketing depends on accurate configuration item (CI) data, including current ownership, service dependencies, and asset state, to make routing and priority decisions that reflect the actual environment.
What AI ticketing automation does in IT operations
AI ticketing automation takes over the mechanical work that consumes most of an ITSM team’s capacity: reading incoming requests, identifying the responsible team, setting priority levels, and, for repeating patterns, resolving tickets without human involvement.
In practice, this breaks down into four functions.
- Classification assigns a ticket type and category based on request content. Using natural language processing, the AI reads the subject, description, and requester history to determine whether a ticket is an incident, service request, change, or problem.
- Routing assigns the ticket to the team or individual responsible for the affected configuration item (CI). This step queries the CMDB for ownership. If the ownership record is accurate, the ticket goes to the right team. If it is six months out of date, it does not
- Priority scoring combines urgency (how quickly the issue needs resolving based on SLA rules) with impact (how many users and services the affected CI supports). Impact is derived from service dependency maps. An accurate service map produces accurate impact scores.
- Auto-resolution handles repeating patterns without human involvement. For procedural requests, password resets, access provisioning, and known software errors, AI agents execute workflows directly. For infrastructure-related tickets, auto-resolution accuracy depends on current CI state, which comes from IT discovery.
These four functions make up the AI ticketing automation pipeline. Each step depends on data quality in ways that most deployment guides underemphasize.
The routing failure nobody talks about
Most articles about AI ticketing automation focus on natural language processing capabilities, deflection rates, and agent productivity gains. They skip the part where the AI routes a ticket to the wrong team because the CMDB ownership record has not been updated since last quarter’s reorganization.
This is the most common failure mode in ITSM AI deployments. An application error arrives as an incident. The AI identifies the affected server from ticket metadata and queries the CMDB for ownership. The record still shows the previous team. The ticket goes to the wrong group. SLA clock runs. The incident escalates. The AI performed exactly as designed. The data was wrong.
A related failure: an incident ticket arrives for a database failure. The AI queries the service dependency map for impact and calculates a medium priority because the map shows the database linked to one internal application. But that service map was last updated five months ago, before two new microservices were connected to the same database. The real blast radius is four services, two of them customer-facing. The priority score misses this entirely.
These are not edge cases. They are predictable outcomes when discovery-driven CMDB updates are not part of the AI ticketing deployment plan.
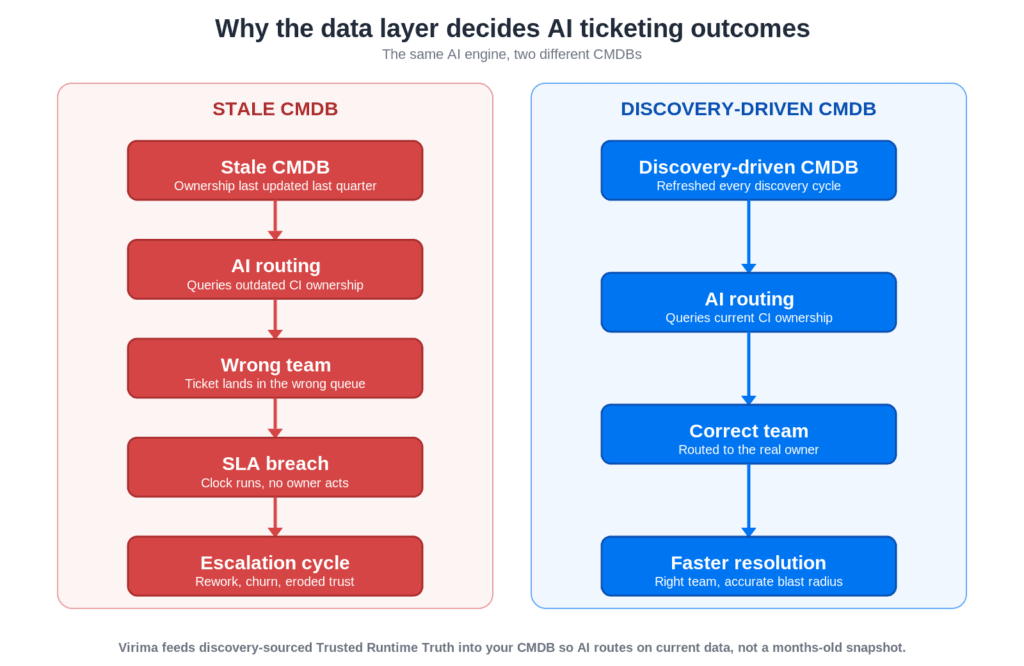
Virima’s approach is direct: instead of relying on manually maintained CMDB records, discovery cycles run on a defined schedule, updating CI ownership, service dependencies, and asset state so the data feeding AI routing decisions reflects the current environment. The result is AI ticketing automation built on Trusted Runtime Truth—discovery-sourced CI data the AI can rely on—not on a snapshot from months ago.
Explore Virima’s Trusted Runtime Truth approach
How AI ticketing automation works: the core mechanics
Understanding the mechanics of each step helps IT teams identify where data quality matters most, and where it matters least.
Natural language processing for classification. NLP reads ticket content and categorizes it by type. This step is mostly independent of CMDB data. Where NLP can fall short is when technical identifiers in the ticket, such as hostnames, application names, or IP addresses, have changed since the last discovery run and no longer match CI records in the CMDB.
CI-based routing. Once the ticket is classified and a CI is identified, the AI queries the CMDB for the team or individual who currently owns that asset. This is the single biggest variable in routing quality. An ownership record that is even three months out of date produces incorrect routing in any environment with regular team changes or infrastructure migrations.
Priority scoring from service dependency maps. Priority in AI ticketing combines urgency and impact. Impact is calculated by tracing the affected CI through ViVID™ service maps to identify which services depend on it and how critical those services are. A service map built from discovery data and kept current produces accurate blast radius calculations.
Blast radius for change tickets. Change requests trigger a different AI workflow. Before routing for approval, the AI runs a blast radius check: which other CIs and services would be affected if this change proceeds? This check is only useful when the service map is current. Without it, AI-assisted change automation approves changes it should flag.
Agentic auto-resolution. For repeating, well-understood ticket types, AI agents execute backend actions: account updates, service restarts, license assignments, and workflow triggers. This works reliably for procedural tasks, but infrastructure-related auto-resolution requires current CI status and ownership records, not data from the last scheduled discovery run three weeks ago.
How does AI prioritize IT service tickets automatically?
AI ITSM systems combine urgency and impact to set ticket priority. Urgency comes from SLA rules tied to the ticket type and requester. Impact is calculated by tracing the affected configuration item through service dependency maps to count the number of users and services at risk. When service dependency maps are built from discovery data and kept current, AI priority scores reflect actual blast radius. When they are stale, impact is underestimated.
The role of CMDB and IT discovery in AI ticketing accuracy
The CMDB is the data source AI ticketing tools query to make routing and prioritization decisions. Most ITSM vendors mention CMDB integration as a checkbox feature without addressing the critical question: how fresh is the data the AI is using, and how often does it update?
Three CMDB capabilities determine AI ticketing quality.
CI ownership accuracy. Every routing decision traces back to a current ownership record. When Virima’s IT discovery runs agentless scanning, agent-based probing, and API-based cloud asset discovery across AWS and Azure, it updates ownership records based on what it finds in the actual environment. AI routing built on these records routes correctly even after org changes and infrastructure migrations.
Service dependency maps. ViVID™ service maps show how applications, servers, databases, and middleware relate to each other. For AI ticketing, this translates directly into blast radius calculation for incidents and change impact scoring for change requests. A service map built from discovery data and refreshed through ongoing discovery cycles reflects actual application dependencies, not the architecture from the last manual update.
Multi-source reconciliation. Large IT environments pull CI data from multiple sources: agent-based discovery, agentless scanning, cloud APIs, and ITSM platform imports. Without reconciliation, the same CI appears under different names with conflicting ownership and relationship records. Virima’s multi-source data reconciliation merges these into a single authoritative CI record, drawing on proven CMDB discovery techniques. AI routing that queries this record does not encounter conflicting entries.
The IT asset management layer adds a fourth dimension: asset lifecycle state. When a server is approaching end-of-life, or when a software license is nearing expiration, that context affects both the priority of related tickets and the routing logic for ITAM-related service requests.
AI ticketing automation use cases for IT operations teams
The following five use cases show where discovery-driven CI data directly shapes AI ticketing outcomes.
- Incident routing by current CI owner. An application error arrives as an incident. AI identifies the CI from ticket metadata, queries the CMDB for current ownership, and routes to the responsible team in seconds. When discovery data keeps ownership records current, routing holds accurately even after org changes, team restructures, or infrastructure migrations that would otherwise produce stale records. This is the foundation of CMDB-backed incident management that reduces MTTR.
- Change ticket blast radius check. A change request arrives for a database server patch. Before approving or routing for human review, the AI runs a blast radius check against the ViVID™ service map: which services depend on this database, and how many users would be affected during the change window? This check identifies changes that should be escalated for human approval before they are auto-approved. See how this fits into modern IT change management tooling.
- ITAM-linked asset lifecycle tickets. Virima’s IT asset management tracking flags hardware and software approaching end-of-life or end-of-support dates. These events trigger automated ticket creation with asset context pre-populated, routed to the current owner, at the right time. This reduces the manual tracking that typically delays EOL remediation and creates compliance gaps.
- Problem management and pattern detection. When multiple incident tickets reference the same CI or service over a short period, AI can escalate to a problem record. This pattern detection requires consistent CI identifiers. If the same physical server appears under three different CI names because of CMDB duplication, the AI misses the cluster. Discovery-driven CMDB normalization ensures incidents referencing the same asset share a consistent CI identifier.
- Self-service request fulfillment. Service requests for software access or hardware provisioning route and fulfill faster when CI data reflects current license availability (from ITAM) and current infrastructure capacity (from discovery). AI can pre-approve requests that fit within policy and available capacity, but that calculation requires accurate, current asset data to produce reliable decisions.
What makes AI ticketing automation accurate in ITSM?
AI ticketing accuracy in ITSM depends on three data quality factors: current CI ownership records so routing goes to the right team, accurate service dependency maps so priority scoring reflects the real blast radius, and up-to-date asset state so auto-resolution acts on the current infrastructure. When these three are maintained through high-frequency IT discovery cycles, AI routing decisions reflect the current environment.
What to look for when evaluating AI ticketing and automation solutions
The marketing capabilities of AI ticketing tools are straightforward to compare. The harder questions are about the data layer each solution depends on.
- How does the tool get CI data, and how often does it refresh? A CMDB connection is the baseline. The real question is whether the AI routing engine refreshes CI ownership and service dependencies on a schedule that matches how fast your environment changes. Manual CMDB maintenance always lags. Solutions where discovery is built into the data pipeline close this gap.
- Does it support your ITSM platforms natively? Virima integrates bi-directionally with ServiceNow, Jira Service Management, Ivanti, Xurrent, and Halo, among others. Native bi-directional integrations mean CI data, ownership records, and service maps flow into the ITSM without custom data pipelines.
- Does impact scoring use service dependency maps? Impact calculated from single-CI analysis misses cascade failures. Solutions that integrate service dependency maps score impact more accurately and flag change risks before approval that single-CI analysis would miss.
- Can it handle multi-source CI data without duplication? Enterprise environments pull CI data from multiple sources. Without reconciliation, AI routing encounters conflicting CI records. Ask vendors how duplicate records are resolved and how ownership conflicts are handled when two sources disagree.
- Is there an audit trail for automated decisions? When AI routes or resolves a ticket automatically, the audit log should capture what data the decision was based on: which CI record, which ownership version, which service map iteration. This matters for post-incident reviews, change governance, and compliance reporting.
- Does it support policy-aware routing? Beyond pattern-based ML routing, policy-aware routing enforces explicit rules: change tickets above a certain blast radius always require human approval; incidents on CIs tagged under a compliance scope always route to the security team. This layer requires CI classification data from the CMDB and sits above the ML model.
- How does it handle escalation with context? When AI cannot resolve a ticket autonomously, the escalation should include full CI context: affected services, recent changes to the CI, current ownership, blast radius. Human agents who receive this context cut resolution time compared to agents receiving bare ticket content.
Manual CMDB vs discovery-driven CMDB for AI ticketing
| Data-layer factor | Manually maintained CMDB | Discovery-driven CMDB (Virima) |
|---|---|---|
| CI ownership freshness | Degrades after each reorg or migration | Refreshed every discovery cycle |
| Service dependency maps | Updated ad hoc, often months stale | Updated as new dependencies are detected |
| Impact / blast-radius scoring | Based on single-CI or outdated maps | Based on current ViVID™ service maps |
| Duplicate / conflicting CIs | Common across multiple sources | Reconciled into one authoritative record |
| Net effect on AI routing | Confident but wrong decisions | Decisions reflect the current environment |
How Virima feeds discovery-driven data into your ITSM’s AI engine
Virima does not replace ITSM ticketing platforms. It provides the discovery-driven Trusted Runtime Truth layer—a continuously refreshed, discovery-sourced view of CI ownership, dependencies, and state—that makes AI decisions inside those platforms accurate.
Virima’s IT discovery runs through agentless scanning using WMI, SSH, and SNMP protocols, agent-based probing on Windows, macOS, and Linux endpoints, and API-based cloud asset discovery across AWS and Azure environments. Discovery outputs populate and refresh the CMDB automatically, eliminating the drift between what ITSM records assume and what the infrastructure actually contains.
ViVID™ service maps keep service dependency data current as infrastructure changes. When discovery detects a new dependency, such as a microservice connecting to a database not in the previous service map, ViVID™ reflects that change in the map the ITSM platform queries for blast radius scoring. The service map that feeds AI impact calculations stays aligned with the actual architecture.
CMDB health scoring gives IT teams visibility into where CI data is most reliable and where it needs attention, so teams can direct remediation effort at the areas most likely to cause AI routing failures.
For organizations running ServiceNow, Virima’s bi-directional CMDB sync pushes discovery-sourced CI data and relationship maps directly into the ServiceNow CMDB, giving ServiceNow’s AI workflows accurate, current data for routing, impact scoring, and blast radius analysis. The same applies to Jira Service Management, where CI-to-issue linking surfaces asset context inside Jira’s automation workflows. Ivanti, Xurrent, and Halo share the same integration pattern. For the strategic case behind this approach, see why AI agents need Trusted Runtime Truth.
See discovery-driven CI data feed your ITSM’s AI engine — schedule a Virima demo
What role does CMDB play in AI ticketing automation?
The CMDB is the primary data source for AI ticketing decisions: CI ownership determines routing, service dependencies determine impact and blast radius, and asset state determines resolution options. When CMDB data is populated and refreshed through scheduled IT discovery, AI ticketing tools make routing and prioritization decisions that reflect the current environment rather than a static historical snapshot.
Common mistakes when deploying AI ticketing automation
Enabling AI routing before auditing CI ownership. This is the most common deployment mistake. The AI routing engine goes live, but CMDB ownership records have not been reviewed since the last org restructure. The result is high misrouting rates in the first 90 days that erode trust in the tool before it gets a chance to prove its value.
Treating deflection rate as the only success metric. Deflection measures how many tickets the AI handles without human involvement. It says nothing about whether the AI handled them correctly. An AI that auto-closes incidents without resolving the root cause produces a high deflection rate alongside low satisfaction scores. Pair deflection metrics with resolution accuracy and ticket reopen rates.
Going live without completing service dependency maps. Many organizations turn on AI ticketing before service mapping is finished. Impact scoring defaults to single-CI analysis, and the AI underestimates blast radius for complex incidents. High-severity incidents get assigned medium priority because the service map does not show the full dependency chain.
Not refreshing CI ownership after org changes. Team restructures, ownership transfers, and application migrations create ownership gaps in the CMDB that surface only when a ticket misroutes. Running discovery-based ownership reconciliation before and after major org changes keeps routing accurate through transitions that would otherwise create data gaps.
Over-automating before validating resolution patterns. Auto-resolution requires validated patterns for each ticket type before enabling it at scale. Start with the highest-volume, lowest-risk ticket types. Confirm that the AI’s resolution actions are correct in a monitored pilot before expanding to broader automation.
What are the prerequisites for AI ticketing automation in ITSM?
Three prerequisites improve AI ticketing outcomes before a deployment goes live: current CI ownership records in the CMDB, updated through scheduled IT discovery; accurate service dependency maps covering the services that AI impact scoring will reference; and validated auto-resolution patterns for the ticket types the system will handle autonomously. Organizations that address all three before enabling AI routing report measurably fewer misrouting incidents in the first 90 days.
Building AI ticketing that stays accurate as your environment changes
The long-term value of AI ticketing automation depends on whether the data layer can keep pace with infrastructure change. An AI routing engine querying a CMDB snapshot from four months ago is working with an increasingly inaccurate picture of the environment. As cloud footprints grow, containers spin up and down, and teams reorganize, the gap between CMDB records and actual infrastructure grows wider.
Scheduled discovery cycles close that gap. When Virima’s discovery runs on a defined schedule, CMDB records reflect recent changes. CI ownership updates when a server migrates to a new team. Service dependencies update when a new connection is detected. Asset state updates when a device changes configuration.
This data freshness is what allows AI ticketing tools to improve over time rather than degrade. The AI learns from past routing decisions, but those learnings only produce better outcomes if the underlying CI data stays accurate. With discovery-driven Trusted Runtime Truth feeding the CMDB, AI ticketing tools have a consistent, accurate foundation, and IT teams spend less time correcting misroutes and more time on work that requires human judgment.
See how Virima supports intelligent ITSM automation — schedule a demo
Frequently asked questions: AI ticketing automation in IT operations
Why do AI ticketing systems route tickets incorrectly?
Most misrouting in AI ITSM tools traces back to stale CI ownership data in the CMDB. When a CI is assigned to a team that no longer owns it because of a migration, org change, or infrastructure update not reflected in the CMDB, the AI routes to the wrong team. Fixing the data layer, not the AI model, resolves most routing failures.
What is the difference between AI ticketing automation and traditional rule-based routing?
Traditional routing uses explicit conditional rules: if ticket type equals hardware failure, route to the infrastructure team. AI routing uses machine learning models trained on historical ticket data to infer the correct team and priority from ticket content and CI context. AI handles ambiguous tickets better and adapts to new patterns over time, but both approaches depend on accurate CI data for routing logic to produce correct results.
How much can AI reduce IT ticket resolution time?
Research from TeamDynamix indicates AI can reduce ticket resolution time by 40 to 90 percent depending on ticket type and automation depth. Deflection rates, meaning tickets resolved without human involvement, range from 30 to 60 percent. The higher end of both ranges applies to organizations with accurate CMDB data, clear service ownership records, and validated auto-resolution patterns for their most common ticket types.
How does Virima improve AI ticketing in ServiceNow?
Virima integrates bi-directionally with ServiceNow to push CI data, relationship maps, and current ownership records into the ServiceNow CMDB. This gives ServiceNow’s AI and automation workflows accurate, current data for incident routing, impact scoring, and blast radius analysis. CI data populated by Virima’s discovery replaces manually maintained records that degrade over time as the environment changes.
Does AI ticketing automation work for change management?
Yes. Change ticket automation is one of the highest-value use cases for IT operations teams. AI can run pre-approval blast radius checks, flag changes affecting high-criticality services, route change tickets to the appropriate approvers, and auto-approve low-risk, pre-authorized changes. The quality of these decisions depends directly on how current and complete the service dependency maps are, which is why discovery-driven service mapping is a prerequisite for effective AI change automation.
Which ITSM platforms does Virima integrate with for AI ticketing?
Virima integrates bi-directionally with ServiceNow, Jira Service Management, Ivanti, Xurrent, and Halo, pushing discovery-sourced CI data, ownership records, and service maps into each platform’s CMDB. This gives the ITSM platform’s own AI workflows current data for routing, impact scoring, and blast-radius analysis without custom data pipelines.
━





