What Is Change Intelligence and Why Your IT Team Needs It
Change intelligence is the practice of using discovery-sourced infrastructure data, service dependency maps, and aggregated risk signals to make better decisions before, during, and after every IT change. It goes beyond standard change management process. It gives your team the context to understand what a change will actually affect, not just how to log and route it for approval.
Standard change management tells you the steps to follow. Change intelligence tells you whether the data behind those steps is trustworthy.
Your CMDB is the foundation of every impact analysis your team runs. When discovery keeps that CMDB current, every blast radius calculation reflects your actual environment. When it doesn’t, your change advisory board (CAB) is approving changes based on guesswork. Change intelligence closes that gap by connecting live CMDB data to your change workflows in a way that makes every approval a governed, defensible decision.
Why Traditional Change Management Falls Short
Most IT teams run change management on a mix of spreadsheets, manually updated CMDBs, and institutional memory. Even mature ITSM shops run into the same problem: the change looks low-risk until something breaks. According to Prosci, roughly 70% of change initiatives fail, and incomplete visibility into downstream impact is a consistent contributor in IT environments.
There are three root causes worth understanding.
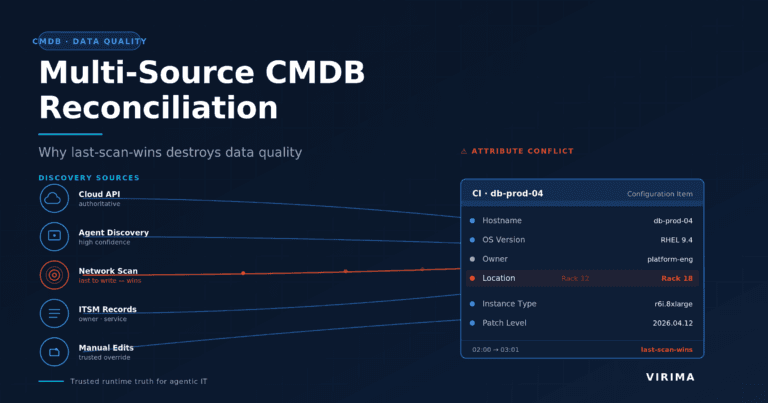
Stale CMDB data. A CMDB that teams update manually falls behind your actual environment within days. Shadow IT, cloud sprawl, and untracked configuration drift widen the gap every week. By the time a change hits the CAB, the dependency data in the change record may already be outdated.
Missing relationship context. Most change records describe the target CI. They don’t show the services built on top of it, the downstream systems that depend on it, or the other open changes already touching related CIs. Without that context, your impact analysis is incomplete.
Disconnected risk signals. Risk register items, open vulnerabilities, previous incident associations, and concurrent change conflicts all live in separate systems. Pulling them together manually before a CAB meeting takes time your team doesn’t have.
Change intelligence addresses all three. It doesn’t replace your change management process. It makes the data your process runs on accurate enough to trust.
The Three Pillars of Change Intelligence
1. Discovery-Driven Infrastructure Accuracy
Change intelligence starts with an accurate, up-to-date picture of your IT environment. That means your CMDB must be populated and refreshed by IT discovery running on a high-frequency schedule, not manual updates. When discovery cycles across your hybrid environment regularly, your configuration items reflect what actually exists rather than what someone recorded last quarter.
This matters most at the moment of change planning. If your CMDB shows the target server’s current configuration, installed packages, running services, and active network connections, your change planner has real data to work with. If the CMDB is stale, every risk estimate is an approximation.
2. Live Service Dependency Maps
Individual CI data isn’t enough. You need to see how CIs connect. A server patch affects every application that runs on that server, and every business service built on those applications. ViVID™ Service Mapping builds dynamic dependency maps from your CMDB relationship data, giving change engineers and CAB reviewers a visual graph of impact scope before the change window opens.
These maps update as your environment changes. When you pull up a ViVID™ service map during change planning, you see the current state of dependencies, not a six-month-old architecture diagram someone exported to Visio.
3. Aggregated Risk Context
The third pillar is context. Change intelligence aggregates risk signals from across your environment and surfaces them in the change record. This includes open vulnerabilities on affected CIs, known compliance obligations, concurrent change conflicts on related infrastructure, and historical incident patterns linked to the target service.
A change approver with all of that context makes a different decision than one who only sees a change title and a manually entered risk score.
How CMDB Data Powers Change Intelligence
The CMDB is the foundation of change intelligence. Every impact analysis, every blast radius calculation, and every approver routing decision flows from the accuracy of your CMDB data.
When a change record targets a specific CI, a change intelligence system traverses the CMDB relationship graph. It identifies every CI that depends on the target, every business service composed of those CIs, and every stakeholder who owns a piece of the impact scope. That traversal is only as reliable as your CMDB’s relationship data.
This is why discovery-driven CMDB data differs from manually maintained CMDB data. High-frequency discovery cycles find relationships your team hasn’t explicitly documented. They capture configuration state at the moment of change planning, not the last time someone updated a record. They also catch the middleware server your documentation still shows as decommissioned, but that’s actually running three services in production.
To understand how to keep your CMDB data accurate enough to support change intelligence, Virima’s CMDB best practices guide is a practical starting point.
Blast Radius Visibility: Knowing What Will Break Before You Touch It
Blast radius is the full scope of impact if a change causes an unintended failure. In change intelligence, blast radius visibility is the difference between a confident approval and a risky bet.
Traditional change planning estimates blast radius based on what the change planner knows about the target CI. Change intelligence calculates blast radius from your CMDB’s actual relationship graph. The result is a visual map showing every downstream CI, service, and business function in the impact scope, including components that no one on the change team thought to include.
ViVID™ Service Mapping surfaces this automatically. When you open a change record, ViVID™ renders the dependency map for the target CI. You see what the change touches directly. You also see what it touches indirectly. You see which other open change records overlap with your impact scope. You see which business services your SLA obligations attach to.
That visibility changes the conversation at the CAB table. Instead of debating risk estimates based on memory, your team discusses specific dependencies and decides whether to proceed, reschedule, or split the change into smaller scopes.
For a detailed look at how Virima implements blast radius visibility during change planning, see the IT change management and change impact analysis use case page.
Change Intelligence in Action: Three Scenarios
Let’s put this in operational terms. Here are three scenarios where change intelligence closes the gap that traditional change management leaves open.
The Undocumented Dependency
Your team plans a database upgrade. The change record lists the target server and the two applications your team knows run on it. Your CMDB, refreshed by the latest discovery cycle, shows a third application connecting to that database. It belongs to a different business unit and wasn’t in the original change scope. Change intelligence surfaces this before the change window opens. Your team extends the stakeholder notification list and adjusts the rollback plan. The upgrade proceeds without a surprise outage.
The Concurrent Change Conflict
Two teams submit changes in the same week. One targets a middleware layer. Another targets the network switch that the middleware depends on. Without change intelligence, both changes proceed independently. The combined impact scope is much larger than either team anticipated. With change intelligence, the CMDB relationship graph flags the overlap during approval routing. Both changes are rescheduled to separate windows with adequate buffer time between them.
The High-Risk CI
A routine patch targets a server that your risk register flags with an open vulnerability and two prior incident associations in the last 90 days. A standard risk score field might classify this as a low-risk change based on its scope size. Change intelligence aggregates the full risk context and escalates the record to CAB-level review. The CAB schedules the patch during a maintenance window with a dedicated rollback team standing by.
In each case, the change management process didn’t change. The data feeding that process did.
Integrating Change Intelligence Into Your ITSM Workflows
Change intelligence is not a replacement for your ITSM platform. It’s a data layer that sits under it. Your change management workflows in tools like Jira Service Management or ServiceNow stay intact. Change intelligence enriches the data those workflows act on.
The integration works in both directions. When a change record is created in your ITSM tool, CMDB relationship data flows in to populate the impact scope and the approver list. After the change executes, discovery verifies the post-change configuration state and writes the diff back to the change record as a timestamped audit record.
This closes the loop between change management and your CMDB. Every change becomes a data point that improves the accuracy of your environment model. Over time, your change intelligence system accumulates a historical record of which CI types carried higher real-world risk and which change patterns have previously caused incidents.
Teams using Ivanti and Xurrent as their ITSM platform follow the same pattern. The CMDB integration surfaces the same change intelligence layer regardless of which tool manages the change ticket. The goal is not to move your team to a new platform. It’s to make the platform you already use act on better data.
IBM’s December 2025 analysis of AI in change management notes that the most effective change programs combine process rigor with data quality. Process tells your team what to do. Data quality determines whether the decisions your process produces are trustworthy.
Pre-Change and Post-Change Configuration Verification
One capability that often gets overlooked in change intelligence is configuration verification. Before the change window opens, a targeted discovery scan captures the current configuration state of every CI in scope. This becomes the pre-change baseline.
After the change executes, discovery runs again on the same CI set. The post-change scan results compare against the baseline. Expected changes (those specified in the change record) are confirmed. Unexpected configuration drift is flagged for investigation by the change manager.
This verification model produces two outputs. First, it creates a timestamped audit record for every change, which supports compliance reviews and post-incident analysis. Second, it catches unintended changes before they become future incidents hiding in your environment.
EMA’s research report on ServiceOps, outages, and AI readiness found that CMDB accuracy and change verification are directly linked to lower incident rates in mature IT organizations. This connection reflects a core principle of change intelligence: good data going into a change window produces better outcomes coming out of it.
Change Intelligence and Your CAB: A Better Conversation
Change advisory boards exist to review proposed changes and catch risks that individual change planners might miss. But a CAB is only as effective as the information in front of it.
When CAB members review a change record that contains a ViVID™ service map showing the full blast radius, a risk register summary for all affected CIs, a list of concurrent changes on related infrastructure, and a pre-change baseline configuration snapshot, they ask better questions. They focus the conversation on specific dependencies rather than generic risk ratings.
That shift changes what the CAB is actually doing. Instead of acting as a process gate, the CAB becomes a decision support forum. Members bring domain expertise to a specific, well-scoped risk question rather than applying a generic scoring rubric to an incomplete change record.
Splunk’s March 2025 analysis of IT change management practices describes this transition as moving the CAB from approval authority to risk advisory function. That transition depends on your team having the data to support it. Change intelligence supplies that data.
If you’re looking for a broader set of operational best practices to pair with change intelligence, the Virima top change management best practices guide covers process, tooling, and ITIL 4 alignment in one place.
How Virima Delivers Change Intelligence
Virima delivers change intelligence through three capabilities working together.
First, high-frequency discovery cycles. Virima’s IT discovery engine runs across your on-premises and cloud environments, including AWS and Azure via API-based discovery, on a configurable schedule. It populates your CMDB with current CI data and relationship records without manual maintenance effort.
Second, ViVID™ Service Mapping. ViVID™ builds dynamic dependency maps from your CMDB data. During change planning, ViVID™ renders the blast radius for any proposed change, showing every affected CI, service, and stakeholder in the impact scope. Change engineers and CAB reviewers see the visual dependency graph directly in the change record.
Third, aggregated change context. Virima’s change management module aggregates CMDB relationship data, risk register items, concurrent change conflicts, and historical incident signals into every change record. Approver routing derives from actual CI ownership data in the CMDB, not from a manually maintained approver list.
The result is a change process where every approval decision rests on Trusted Runtime Truth: live, explainable, discovery-sourced infrastructure data. For a closer look at the layer that powers this, visit Virima’s Trusted Runtime Truth page.
For a detailed breakdown of how Virima supports ITIL v4 Change Enablement including standard, normal, and emergency change workflows, see how Virima supports ITIL change management.
| A What is change intelligence in IT? Change intelligence is the use of discovery-sourced CMDB data, service dependency maps, and aggregated risk signals to improve IT change decisions. It gives change planners and CAB reviewers accurate blast radius context before change windows open, so approvals are based on real infrastructure data rather than manually estimated risk scores. |
| How does change intelligence differ from standard change management? Standard change management defines the process for logging, routing, and approving changes. Change intelligence provides the data layer that process runs on. Without accurate CMDB data and live service dependency maps, change management process produces approvals based on outdated or incomplete infrastructure information regardless of how mature the process is. |
| What data does change intelligence use? Change intelligence draws on CI configuration data from the CMDB, service dependency relationships from maps like ViVID™, open vulnerability and risk register records, concurrent change schedules, and historical incident associations. Together, these signals give every change record accurate risk context that a manual process cannot replicate at scale. |
| Why does CMDB accuracy matter for change management?Every impact analysis in your change workflow depends on the accuracy of the CMDB it reads from. A stale CMDB produces incomplete blast radius calculations that miss undocumented dependencies. A discovery-driven CMDB, refreshed by high-frequency scans, produces impact analyses that reflect the actual state of your environment at the time of change planning. |
| What is blast radius in IT change management?Blast radius refers to the full scope of impact if a change causes an unintended failure. Change intelligence calculates blast radius by traversing CMDB relationship data to identify every dependent CI, service, and business function connected to the change target, including dependencies that teams haven’t explicitly documented. |
Change Intelligence Turns Uncertainty Into a Governed Decision
Every change carries some risk. Change intelligence doesn’t eliminate that risk. It gives your team the data to make a confident, defensible decision about it.
When your CMDB reflects your actual environment, your blast radius calculations are accurate. When your ViVID™ service map shows every dependency in scope, your CAB asks better questions. When your change record aggregates risk signals from discovery, vulnerability data, and incident history, your approvals reflect operational reality rather than optimistic estimates.
The shift change intelligence makes is specific: from guesswork to governed decision-making. Your changes don’t become easier to approve because risk disappears. They become easier to approve because the risk is visible, scoped, and traceable.
Frequently Asked Questions
What’s the difference between change intelligence and ITIL change management?
ITIL change management, called Change Enablement in ITIL 4, is a process framework for evaluating, authorizing, and coordinating IT changes. Change intelligence is the data and visibility layer that makes that process accurate. ITIL defines the steps to follow. Change intelligence determines whether the data behind those steps is trustworthy. Both are necessary. One without the other produces either ungoverned decisions or a well-structured process built on bad data.
Can change intelligence work with my existing ITSM platform?
Yes. Change intelligence integrates with existing ITSM tools rather than replacing them. Platforms including Jira Service Management, ServiceNow, Ivanti, and Xurrent can receive CMDB relationship data to enrich change records. The change workflow stays in your ITSM tool. The intelligence layer comes from your CMDB and the discovery engine that keeps it current.
How often does discovery need to run to support change intelligence?
The right frequency depends on how quickly your environment changes. For most enterprise environments, discovery should run at least daily on critical infrastructure. High-frequency discovery cycles on production services give your change records current data rather than week-old snapshots. Virima’s discovery engine supports configurable scan frequencies so you can match the cadence to your environment’s rate of change.
What happens when post-change discovery finds an unexpected configuration?
Post-change discovery compares the current configuration state against the pre-change baseline captured before the change window opened. Unexpected differences surface in the change record. The change manager reviews the diff, determines whether the unintended change is safe, and either accepts the state or triggers a rollback procedure. This catch mechanism works because the pre-change baseline exists as a timestamped reference point tied directly to the change record.
Is change intelligence only relevant for large enterprise IT teams?
No. Any IT organization managing changes across a hybrid environment benefits from change intelligence. Smaller teams often have fewer people available to manually research blast radius and aggregate risk signals before a change window. This makes discovery-driven change intelligence more practical for them, not less. The effort of building a manual impact analysis for every change is proportionally higher on a small team than on a large one with dedicated change analysts.