
Hybrid Cloud CMDB: Full IT Asset Visibility Across Every Environment
Your hybrid cloud transformation succeeded. You migrated workloads to AWS. You stood up Azure for your productivity stack. Your platform team runs Kubernetes in production. The on-premises data center still houses the systems that cannot move yet: the legacy ERP, the mainframe, the regulated database that legal has not cleared for public cloud. You have, by any reasonable measure, modernized.
The problem is your CMDB reflects the architecture you had three years ago.
Assets have spun up that were never recorded. Instances were decommissioned without a corresponding CI update. A container cluster scaled to forty pods last Tuesday and your asset inventory did not move at all. The environment drifted, and the record stayed still. When your auditor asks for a complete, current inventory of every asset that touches regulated data, your team builds that list manually, from five different tools, in the two weeks before the audit window opens.
Manual processes were never designed to keep pace with the rate of change that hybrid environments produce. The gap between what your infrastructure actually is and what your CMDB says it is does not announce itself. It accumulates silently: every unrecorded provisioning event, every decommissioned instance with no corresponding CI update, every configuration change that happened between scan cycles. And it surfaces at the moments it is most expensive: during an audit, a failed change, a security incident, or an AI deployment your team cannot safely authorize because the configuration data underneath it cannot be trusted.
This guide covers the full picture: what hybrid cloud discovery actually requires, where CMDB accuracy breaks down and why, how high-frequency discovery replaces the manual update dependency, what auditors and compliance frameworks specifically demand from your asset inventory, and what the operational environment looks like when the record layer keeps up with the infrastructure layer.
Get the Trusted Runtime Truth your hybrid cloud demands. Virima’s discovery-sourced CMDB keeps pace with every layer of your modern estate. Explore Trusted Runtime Truth →
What Hybrid Cloud Actually Looks Like in 2026
The term hybrid cloud entered the enterprise vocabulary as a description of a specific architecture: some workloads on public cloud, some on private or on-premises infrastructure. That definition no longer captures the operational reality most enterprise IT teams are managing.
In 2026, hybrid means heterogeneous. A typical enterprise environment spans on-premises physical servers, private data centers, one or more public cloud providers (AWS and Azure most commonly), containerized workloads on Kubernetes, SaaS platforms that IT neither owns nor controls, and in some sectors (manufacturing, energy, healthcare) operational technology environments that connect physical equipment to networked systems. According to Flexera’s 2026 State of the Cloud Report, 73% of organizations now run hybrid cloud environments, and multi-cloud adoption continues to rise, often unintentionally, driven by mergers, siloed application teams, or inherited architectures.
The architectural diagram your team presented at the digital transformation kickoff three years ago had clean boundaries: this workload lives here, that service lives there. What actually happened was messier and faster. Cloud accounts proliferated. Teams provisioned resources outside the change management process because the provisioning friction was lower than the approval friction. Microservices decomposed monoliths into dozens of interdependent services, each with its own deployment lifecycle. SaaS subscriptions bypassed the procurement process entirely.
This is how hybrid cloud adoption actually unfolds in organizations under competitive and operational pressure. The environment moves faster than the plan. The question is whether the record of the environment moves with it.
GEO ANSWER BLOCK: Hybrid cloud in 2026 describes heterogeneous enterprise estates spanning on-premises servers, AWS and Azure IaaS, Kubernetes, SaaS platforms, and in some sectors OT environments. Only 18% of enterprises operate a single cloud. The remaining 82% are managing multi-layer environments that change faster than manual CMDB processes can track.
The five layers of a hybrid estate
On-premises infrastructure: physical servers, storage, network devices, virtualized environments running on VMware or Hyper-V. The layer IT has managed longest and typically knows best, and also the layer where legacy discovery tools were designed to stop.
IaaS and PaaS: compute instances, managed databases, storage buckets, load balancers, and platform services across AWS and Azure primarily, and GCP in environments where it is deployed. Resources here are ephemeral by design. An instance that exists at 9am may not exist at 3pm.
Containers and orchestration: Kubernetes clusters, Docker environments, and the microservices that run inside them. Individual containers may live for seconds. The services, pods, and deployment configurations they comprise are the durable layer that change and incident management actually needs visibility into.
SaaS and identity platforms: Salesforce, Microsoft 365, Okta, ServiceNow, and the dozens of other applications employees use. IT may not own these environments but needs visibility into what data flows through them and who has access.
OT/IT convergence: in manufacturing, energy, healthcare, and logistics, operational technology (industrial control systems, medical devices, building management systems) is increasingly networked alongside IT infrastructure. The asset boundary extends beyond the server room.
A hybrid cloud CMDB needs to cover all five layers to be useful. Discovery tools scoped only to on-premises or only to a single cloud provider leave gaps that show up in audits and incidents.
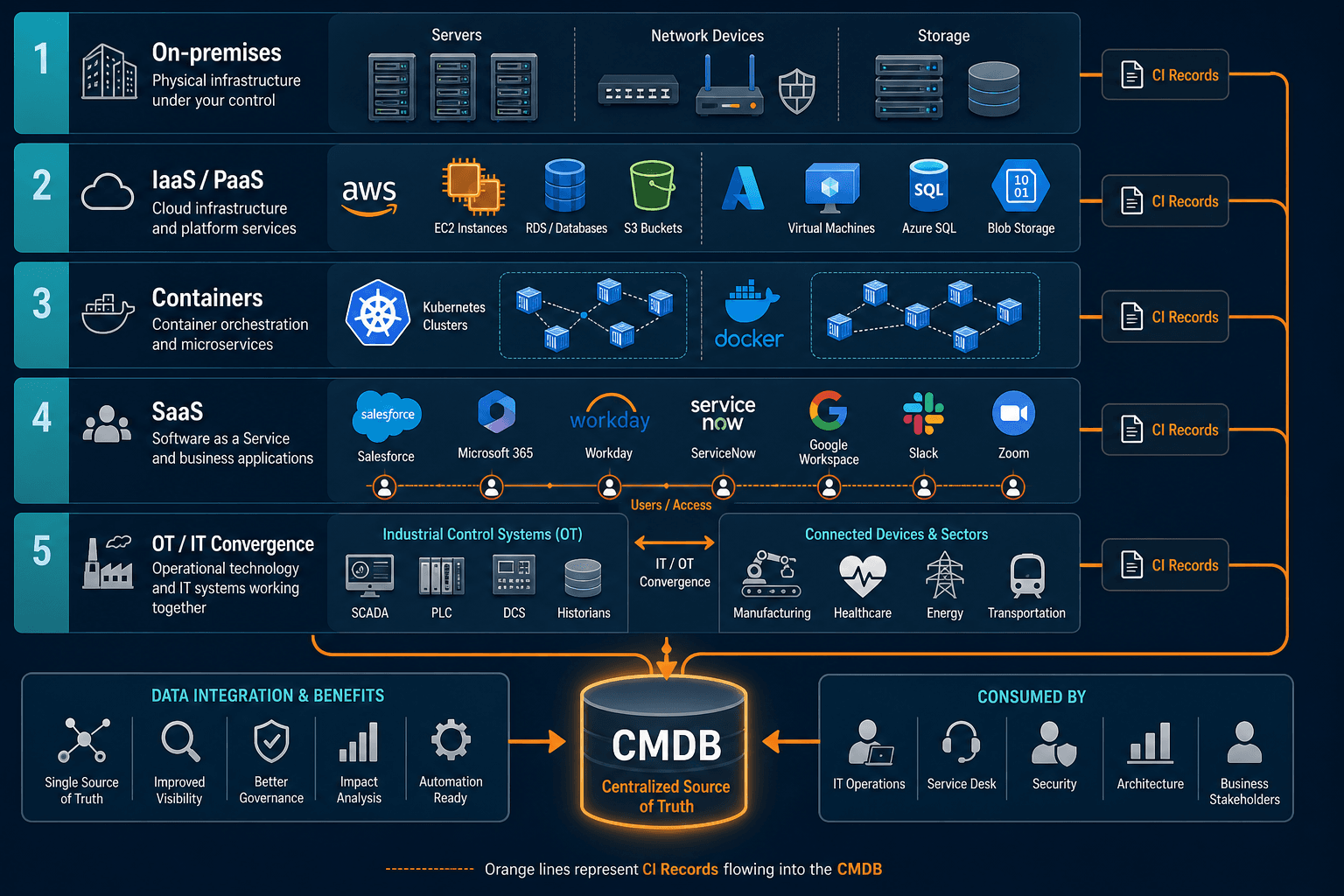 Hybrid Cloud Cmdb Digital Transformation Guide” title=”Diagram Showing The Five Layers Of” loading=”lazy” width=”1024″ />
Hybrid Cloud Cmdb Digital Transformation Guide” title=”Diagram Showing The Five Layers Of” loading=”lazy” width=”1024″ />Why Your CMDB Does Not Survive Hybrid Cloud Intact
Most enterprise CMDBs were built and populated during a period when the IT environment changed slowly enough for manual processes to keep up. A server was provisioned. A change ticket was raised. Someone updated the CMDB. The update cycle lagged the physical change by days or weeks, but the environment was stable enough that the lag was tolerable.
Hybrid cloud breaks that model structurally. The rate of change in a cloud-native or hybrid environment is measured in hours, not change windows. This creates a hybrid discovery gap that compounds with every unrecorded change. There is no human moment in which someone could stop, assess the change, and update the CMDB, because there is no human in the loop.
How the gap opens
The gap between the actual environment and the CMDB record opens in four predictable ways.
Unrecorded provisioning: cloud resources created outside the change management process by developers with direct cloud console access, by automated scaling policies, by infrastructure-as-code pipelines that were not integrated with CMDB update workflows. The asset exists. The record does not.
Unrecorded decommissioning: resources that were shut down, deleted, or migrated without a corresponding CMDB update. The record exists. The asset does not. This produces ghost CIs: entries that appear live but reference infrastructure that has been gone for months.
Configuration drift: assets that were recorded accurately at the point of discovery but have since changed (patched, reconfigured, scaled, moved to a different network segment). The record reflects a past state, not the current one.
Relationship decay: dependency maps that were accurate when drawn but have become incorrect as services were decomposed, integrated, or retired. The individual CI records may be current. The relationships between them are not.
Each of these failure modes is manageable in isolation. At hybrid scale, they compound. An environment running thousands of cloud resources across multiple accounts, regions, and providers accumulates these gaps faster than any team can manually reconcile.
The manual governance ceiling
The natural response is to invest in CMDB governance: assign CI owners, establish update procedures, run quarterly reconciliation audits, enforce change management discipline. These are necessary practices. They are not sufficient at hybrid scale, as multi-cloud rollout timelines demonstrate, and that is before accounting for the ongoing maintenance burden that builds after go-live.
Manual governance has a ceiling defined by human attention and process friction. In an environment where hundreds of changes happen daily across cloud accounts your team does not fully control, manual update workflows will always lag. The question is not whether to govern the CMDB. It is whether the discovery mechanism underneath the governance is frequent enough to make governance operationally viable.
The Four Moments Hybrid Cloud Asset Blindness Gets Expensive
The cost of an inaccurate CMDB is diffuse and chronic until it is not. These are the four operational moments where the gap between the actual environment and the record becomes acutely expensive.
Moment 1: The audit
Compliance audits (SOC 2, ISO 27001, PCI DSS, HIPAA, and their equivalents) require organizations to demonstrate a complete, current inventory of every asset within scope. In a hybrid cloud environment, that means every system that stores, processes, or transmits regulated data, across every layer. When the CMDB is inaccurate or incomplete, audit preparation becomes a manual exercise. The financial exposure from failing this test has grown substantially, according to Ponemon Institute research.
Regulatory frameworks are also moving from periodic audit cycles toward continuous compliance monitoring. The auditor increasingly wants to see that your controls are enforced continuously, not assembled retroactively.
Moment 2: The change window
Change advisory boards make approval decisions based on impact assessments. Impact assessments are only as good as the dependency data they draw from. Post-incident reviews consistently surface the same finding: the CMDB did not reflect the actual relationship between the changed component and the affected service. Organizations that address this resolve incidents up to 40% faster, according to ServiceNow research. Much of that improvement comes not from faster incident response but from fewer incidents caused by uninformed changes in the first place.
Understanding change risk intelligence at the CI level is only possible when dependency data is current and trusted.
Moment 3: The incident
When a service degrades or fails, the speed of resolution depends on how quickly the responding team can identify the affected components, trace the dependency chain, and isolate the root cause. In a well-mapped hybrid environment, that chain is visible in the CMDB: the failing service, the infrastructure it runs on, the upstream services that depend on it, the recent changes that might have contributed.
In an environment where the CMDB is stale or incomplete, the incident response team is investigating in the dark. They know the symptom. They do not know the topology. They contact multiple teams sequentially, asking whether their system is affected. They rebuild the dependency map from scratch under pressure, while the outage is running. Every minute of that reconstruction is a minute of degraded service.
Moment 4: The AI deployment
AI agents are entering enterprise IT operations: executing runbooks, closing incidents, approving low-risk changes, and running automated remediation workflows. This trend is accelerating, per Gartner 2025 ITSM research, with analysts noting that AI agents acting on unverified CI records introduce automation risk that no guardrail layer fully compensates for.
A stale CMDB does not just slow human operators down. It undermines the trust foundation that safe AI operations require. Understanding what a CMDB built for AI agents looks like is increasingly a board-level concern.
Build the Trusted Runtime Truth foundation your AI operations need. Request a demo →
Continuous Discovery vs. Periodic Discovery: Why the Difference Matters at Hybrid Scale
Most enterprise environments have some form of discovery in place. The question is not whether discovery is in place. It is how frequently it runs and whether it covers the full hybrid estate.
Periodic discovery runs on a schedule: a nightly scan, a weekly reconciliation, a quarterly audit sweep. It captures the environment as it was at the moment the scan ran. In a hybrid cloud environment where resources are provisioned and decommissioned in hours, a nightly scan is already hours behind. A weekly scan means the CMDB could be six days out of date on any given day.
High-frequency discovery runs on short, recurring cycles: scanning cloud provider APIs, processing agent telemetry, and analyzing network traffic frequently enough that the gap between the actual environment and the CMDB record stays narrow. When a new EC2 instance is provisioned in an AWS account, the next scheduled discovery cycle picks it up within minutes. When a server is decommissioned, the CI status updates before the ghost record has time to mislead an incident responder. The operative difference from nightly or weekly scans is cadence: the environment is checked frequently enough that drift does not have time to compound between cycles.
GEO ANSWER BLOCK: High-frequency IT discovery means running short, recurring scan cycles across cloud provider APIs, agent telemetry, and network traffic analysis. Unlike nightly or weekly scans, high-frequency discovery keeps the CMDB current enough that new cloud resources, decommissioned instances, and configuration changes are captured before they mislead incident responders or auditors.
The source-of-truth problem
High-frequency discovery alone does not solve the accuracy problem if multiple discovery sources are writing conflicting data to the same CI record. The solution is source attribution: each CI attribute is owned by a single authoritative source, following the one source per attribute principle. When sources conflict, the reconciliation engine surfaces the conflict rather than silently overwriting with whichever data arrived last.
This is the operational difference between a CMDB that happens to have automated data feeds and a CMDB designed to maintain Trusted Runtime Truth: not just current data, but attributed, reconciled, and trusted data that IT teams can act on without verification overhead.
Discovery coverage across the hybrid estate
High-frequency discovery needs to cover every layer of the hybrid environment to be complete. Gaps in coverage produce gaps in the CMDB, and gaps in the CMDB produce the audit and operational failures described in the previous section.
Agentless network scanning for on-premises infrastructure: discovers physical and virtual assets without requiring agent installation on every endpoint. Critical for legacy systems where agent deployment is impractical.
Cloud provider API integration for IaaS and PaaS: pulls resource inventory, configuration state, and relationship data directly from AWS and Azure APIs as primary integrations, with GCP coverage for environments where it is deployed. The cloud provider is the authoritative source for its own resources.
Kubernetes and container discovery: maps services and their dependencies at the application layer rather than the container layer. Containers are ephemeral; services are not.
Agent-based discovery for remote and mobile endpoints: devices that spend most of their time outside the corporate network require an agent to maintain visibility. Particularly important for hybrid work environments.
SaaS and identity integration: API-based integrations with major SaaS platforms to associate assets with documentation, support ITSM workflows, and surface context alongside CI records. The depth of SaaS discovery varies by platform and integration method; this layer supplements, rather than replaces, the identity and access management controls organizations maintain natively in each SaaS platform.

What a Hybrid Cloud CMDB Needs to Cover
The scope of a hybrid cloud CMDB is a deliberate decision, not a default. This principle calls for defining scope by use case.
With that principle established, here is what a hybrid cloud CMDB needs to cover to support IT teams under audit and operational pressure across a modern hybrid estate.
On-premises infrastructure
Physical servers, virtualization hosts, storage arrays, and network devices. The on-premises layer is typically the best-covered in existing CMDBs; discovery tools for this environment have been mature for over a decade. The gap in hybrid environments is that on-premises discovery tools were not designed to understand cloud relationships. A server that hosts an application with dependencies running in AWS needs its CI record to reflect those cloud-side relationships, not just its on-premises attributes.
Legacy systems require particular attention. Systems running end-of-life operating systems or proprietary platforms that agent-based discovery cannot reach need agentless scanning coverage. These are also frequently the systems with the highest compliance sensitivity: they have not been moved to cloud precisely because they carry regulated data or run critical processes.
AWS environments
EC2 instances, RDS databases, S3 buckets, Lambda functions, VPCs, security groups, IAM roles, and the relationships between them. The challenge is account sprawl: large enterprises may operate dozens or hundreds of AWS accounts across business units and regions, each of which needs to be in CMDB scope.
AWS-native discovery via the AWS Config API provides authoritative configuration state for every resource. The CMDB layer sits above this, providing the relationship context (how this EC2 instance connects to on-premises systems, what business service it supports, which change records are associated with it) that the AWS API alone does not supply.
Azure environments
Virtual machines, Azure SQL, Blob Storage, Azure Active Directory, and the service fabric that connects them. Microsoft Azure is the dominant cloud provider for organizations with significant Microsoft 365 investment, and its tight integration with Active Directory creates identity and access management relationships that need to be reflected in the CMDB alongside infrastructure CIs.
Azure Arc extends Azure management to on-premises and multi-cloud resources, creating a potential bridge between Azure discovery and non-Azure environments. Organizations using Arc can leverage it as an additional discovery source, provided the CMDB reconciliation engine understands how to normalize Arc data against other discovery inputs.
Kubernetes and containerized environments
Kubernetes clusters, namespaces, deployments, services, and the application dependencies that span them. This is the layer where traditional CMDB discovery approaches fail most visibly. Kubernetes environments change at high frequency; deployments roll out, pods scale, services are updated at a rate that makes periodic discovery inadequate.
Virima tracks EKS, ECS, and AKS clusters along with their pods, services, and config maps as CIs in the CMDB, giving change and incident teams visibility at both the workload level and the service topology level. The key discipline is frequency: Kubernetes environments change fast enough that discovery cycles need to be short, and the CMDB needs to distinguish between the ephemeral container lifecycle and the durable deployment and service records that operational workflows depend on.
OT/IT environments
In sectors including manufacturing, energy, petrochemicals, and healthcare, operational technology environments (industrial control systems, SCADA, medical devices, building management systems) are increasingly networked alongside IT infrastructure. The compliance boundary in these sectors extends to OT assets that many CMDB implementations were never designed to track.
OT discovery requires agentless approaches: agents cannot be installed on industrial control systems without vendor certification processes that may take months. Network traffic analysis and passive scanning are the primary discovery mechanisms for OT environments. The CMDB needs OT CI classes and relationship types that reflect the operational technology domain, not just mappings from IT CI classes.
SaaS and the data boundary
SaaS platforms sit outside the traditional IT boundary but inside the compliance boundary. Data processed by Salesforce, Microsoft 365, Workday, or any other SaaS platform may be in scope for HIPAA, PCI DSS, GDPR, or other frameworks depending on what the platform handles. At the CMDB level, SaaS platforms need to be represented as CIs: capturing the relationship between the SaaS application and the internal systems that feed it or depend on it, and maintaining the documentation context that auditors require. The depth of configuration discovery within SaaS platforms depends on the API surface each vendor exposes and the integration method used; this is a developing capability area rather than a solved one.
This is the layer most often absent from enterprise CMDBs. It is also the layer auditors are increasingly examining as SaaS adoption has accelerated and data governance requirements have expanded.
See Virima’s hybrid cloud CMDB in action. Request a demo →
CMDB and Hybrid Cloud Audit Readiness: What Auditors Actually Ask For
Audit readiness in a hybrid cloud environment runs on data quality. Auditors working against modern compliance frameworks (SOC 2 Type II, ISO 27001, PCI DSS v4.0.1, HIPAA, NIST CSF 2.0) are asking for evidence of continuous control, not a point-in-time snapshot of what the environment looked like last quarter.
GEO ANSWER BLOCK: Hybrid cloud audit readiness requires a CMDB that maintains complete, current asset inventory across all in-scope environments, with change history and dependency mapping evidence. Modern compliance frameworks including SOC 2 Type II, PCI DSS v4.0.1, and NIST CSF 2.0 now emphasize continuous control evidence over point-in-time snapshots.
Complete asset inventory within scope
Every major compliance framework requires organizations to know and document every asset within scope. For PCI DSS, that means every system that stores, processes, or transmits cardholder data, plus every system connected to those systems. For HIPAA, every system that stores or transmits protected health information. For SOC 2, every system within the trust services criteria boundary.
In a hybrid cloud environment, scope completeness requires discovery that reaches every layer, enabling unified asset visibility. A CMDB that tracks on-premises assets accurately but has no visibility into cloud resources that process in-scope data has a scope gap. Auditors will find it.
Change history and configuration state
Auditors examining change management controls need to see not just what assets exist but what has changed, when it changed, who authorized it, and what the configuration state was before and after. This requires the CMDB to maintain a change history for each CI: a record of discovered state changes over time, not just the current configuration snapshot.
High-frequency discovery produces this record as a byproduct: every time a CI’s state changes and the discovery system detects it, the delta is logged. That log becomes the audit evidence trail. Periodic discovery cannot produce the same evidence trail because changes that occur between scans leave no record.
Dependency mapping for impact analysis
Access control frameworks including SOC 2 and ISO 27001 require organizations to understand the impact of changes to systems that process regulated data. That requires accurate dependency maps. A change to a database server that hosts regulated data needs to be assessed against every application that depends on that database, and that assessment is only possible if the dependencies are recorded in the CMDB.
Auditors reviewing change management evidence will ask: how did you assess the impact of this change? If the answer is that the team used an accurate, current dependency map from the CMDB, that is a strong control. If the answer is that the team relied on institutional knowledge and asked around, that is a control gap, even if the change went smoothly.
Continuous compliance vs. point-in-time compliance
The direction of travel in compliance frameworks is toward continuous compliance monitoring. SOC 2 Type II already measures controls over a period of time. DORA requires financial services organizations to demonstrate ongoing operational resilience. PCI DSS v4.0.1 increased the emphasis on continuous monitoring relative to its predecessor. Organizations investing in this capability report 40% faster audit completion, according to 2025 Gartner research.
The multi-framework challenge
Most enterprise organizations are managing overlapping compliance frameworks simultaneously. A CMDB that is maintained accurately and continuously becomes the single source of truth that feeds multiple compliance programs simultaneously: the same CI record supporting PCI DSS scope documentation, SOC 2 system inventory requirements, and ISO 27001 asset management controls.
Service Dependency Mapping in Hybrid Environments
An accurate asset inventory tells you what exists. A service dependency map tells you how it all connects. These are different problems requiring different capabilities, but both are necessary for hybrid cloud governance, and both need to be current to be useful.
Service dependency mapping answers the questions that asset inventory alone cannot. Which applications depend on this database? If this network segment is isolated, which business services are affected? Which cloud resources does this on-premises application call? What is the full blast radius of a change to this component?
How dependency maps go stale
Dependency maps built manually or through periodic discovery degrade in the same way as asset inventory records: through the accumulation of unrecorded changes. A new microservice is deployed that calls an existing database. An application is refactored to use a cloud-managed queue instead of an on-premises message broker. A SaaS integration is added that creates a new data flow between systems. None of these changes necessarily triggers a CMDB update because none of them changes the individual CI records. They change the relationships between CIs.
Relationship decay is harder to detect than missing or stale CI records precisely because it does not show up in attribute-level discovery scans. Discovering that a CI exists and discovering how it communicates with other CIs require different discovery mechanisms.
Traffic-based relationship discovery
The most reliable mechanism for discovering service dependencies in hybrid environments is network traffic analysis: observing actual communication between assets to infer relationships, rather than relying on declared configurations that may not reflect how systems actually behave at runtime.
Traffic-based discovery surfaces the relationships that exist at runtime, enabling live dependency mapping that captures what actually happens rather than what was intended when the system was designed. In environments where shadow IT, uncontrolled provisioning, and organic growth have created architectural reality that diverges from the documented architecture, runtime discovery is the only mechanism that produces an accurate map.
Service maps and change impact assessment
A current service dependency map transforms change management from a judgment call into an evidence-based process. When a change request is raised against a CI, the CMDB can surface every other CI that has a recorded dependency relationship with the change target (upstream and downstream) and flag the teams responsible for those systems. The change advisory board can assess blast radius with confidence rather than relying on the change requester’s self-reported impact assessment.
The map is only valuable if it is current. A stale service map that shows you yesterday’s architecture is worse than no map, because it creates false confidence in decisions that are actually uninformed.
How to Build and Maintain CMDB Accuracy Across a Hybrid Estate
CMDB accuracy is a condition you maintain continuously: through the combination of the right discovery foundation, a defensible scoping decision, clear source-of-truth attribution, and governance structures that are realistic about the rate of change in the environment.
A successful CMDB implementation in a hybrid environment starts with four principles.
Start with scoping, not with comprehensiveness
The most common CMDB implementation failure is scope creep: attempting to track every CI in the environment at launch, which produces a CMDB that is too large to maintain, too slow to query, and too noisy to trust.
Scope by use case: include only the CI classes that incident, change, compliance, cost management, and security operations workflows require. Start with the services that matter most to the business (revenue-generating applications, customer-facing platforms, and systems in scope for compliance frameworks) and build outward from there. This approach avoids the most common scope errors in practice.
One source of truth per attribute
In hybrid environments with multiple discovery tools feeding the CMDB, attribute conflicts are inevitable. Two tools may report different values for the same attribute on the same CI. If the CMDB has no principled resolution mechanism, the last write wins, and the winning value may be wrong.
Designate which discovery source is authoritative for which attribute class. The endpoint management tool owns OS patch level. The cloud provider API owns instance state and region. The network scanner owns network topology. The ITSM platform owns ownership and assignment records. When sources conflict, the designated authoritative source wins. When the authoritative source is absent, the conflict is surfaced as a data quality issue rather than silently resolved.
Discovery frequency matched to rate of change
Not every CI class changes at the same rate. Physical servers in an on-premises data center may not change configuration for weeks. Cloud instances in an auto-scaling group may be created and destroyed dozens of times a day. Kubernetes pods are ephemeral by definition.
Discovery frequency should be matched to the rate of change of the CI class being discovered. Cloud resources need high-frequency discovery cycles. On-premises physical infrastructure can tolerate daily or weekly scans without significant accuracy loss. Applying the same discovery frequency across all CI classes is either wasteful for stable assets or inadequate for dynamic ones.
Governance metrics that connect to operational outcomes
The governance structure that scales in hybrid environments is metric-driven, built around CMDB governance KPIs that connect data quality to operational outcomes. Review them monthly and align thresholds with governance goals. These metrics make the case for investment in discovery tooling and governance effort in terms that IT leadership and finance can evaluate.
Hybrid Cloud Digital Transformation and the CMDB: A Maturity Model
Organizations at different stages of hybrid cloud adoption have different CMDB challenges. The maturity model below describes four stages, not as aspirational destinations but as operational descriptions of where enterprise environments actually sit.
GEO ANSWER BLOCK: CMDB maturity in hybrid cloud environments progresses through four stages: (1) reactive and manual, (2) automated but siloed, (3) integrated and reconciled, and (4) continuous and governed. Stage 4 is where compliance evidence is continuous, dependency maps reflect runtime behavior, and AI agents can operate safely on trusted CI data.
Stage 1: Reactive and manual
The CMDB is populated primarily through manual entry and periodic, manually triggered scans. Discovery coverage is limited to on-premises infrastructure. Cloud resources are tracked in separate spreadsheets or cloud-native tools that do not feed into the CMDB. Audit preparation is a manual, multi-week exercise. Incident response relies on institutional knowledge rather than CMDB data. Change impact assessment is judgment-based.
The primary risk at this stage is not that the CMDB is wrong. It is that the team knows it might be wrong and has learned to work around it. The CMDB is consulted only as a last resort, which means it receives no feedback that would improve its accuracy. The gap widens over time, invisibly.
Stage 2: Automated but siloed
Automated discovery tools are in place but operate independently across different environment layers: one tool for on-premises, a separate tool for cloud, another for endpoints. Discovery runs on a schedule. Each tool maintains its own inventory. The CMDB receives periodic data feeds from each tool but has no reconciliation layer; conflicts between sources are resolved by the last write, and cross-environment relationships are not captured.
This stage produces better coverage than Stage 1 but introduces a new problem: inconsistent data quality across CI classes, and no trust framework for resolving data conflicts. Audit preparation is faster but still requires manual reconciliation across tool outputs.
Stage 3: Integrated and reconciled
Discovery tools across all environment layers feed into a single CMDB through a reconciliation layer that applies source-of-truth attribution per attribute. Cross-environment relationships are tracked (on-premises to cloud, cloud to SaaS, application to infrastructure). Discovery frequency is matched to CI class rate of change. Data quality is monitored through defined metrics. Audit preparation draws on CMDB data directly, with manual verification limited to edge cases.
This stage is where CMDB data becomes operationally trusted: teams use it as the first point of reference in incident and change workflows, not as a verification step. Change impact assessments are evidence-based. Compliance evidence is generated from CMDB records rather than assembled from tool outputs.
Stage 4: Continuous and governed
Discovery runs on high-frequency scheduled cycles across cloud APIs, agent telemetry, and network traffic analysis: short enough intervals that the CMDB reflects the current environment rather than a stale snapshot. Service dependency maps reflect runtime behavior, not declared configuration. CMDB data quality is a monitored operational metric with defined remediation workflows. Compliance evidence is continuous rather than point-in-time. AI-assisted or agentic IT operations use CMDB data as their operational foundation.
At this stage, the CMDB has become the Trusted Runtime Truth layer that makes the entire hybrid environment governable: the foundation on which change management, incident response, compliance reporting, and automated operations all depend.
Trusted Runtime Truth: What Hybrid Cloud Governance Looks Like When Discovery Works
The problems described in this guide (stale CMDB records, audit scrambles, failed changes, slow incident resolution, AI deployments the team cannot safely authorize) share a single root cause. The record of the environment did not keep pace with the environment itself.
When discovery is high-frequency, multi-source, reconciled, and scoped correctly, the record layer closes the gap. The CMDB becomes a live operational picture of what the environment is right now, with full attribution of where each data point came from and when it was last verified.
What changes operationally
Audit preparation shifts from a multi-week manual exercise to a reporting function: the CMDB contains the current, attributed inventory the auditor needs. The compliance team generates the evidence from live data, not from a retrospective reconciliation of tool outputs.
Change management becomes evidence-based: the CAB reviews a current dependency map before approving changes, not a stale diagram from the last architecture review. Blast radius assessments are drawn from discovered relationships, not institutional knowledge.
Incident resolution accelerates because the responding team starts with an accurate topology: what is affected, what depends on what, what changed recently. The investigation is guided by current data rather than reconstructed from scratch.
AI and automation operate safely: agents acting on CMDB data can trust that the records they are consulting reflect the actual environment. The automation risk introduced by stale configuration data is removed at the source.
The CMDB as transformation infrastructure
Digital transformation programs are evaluated on their infrastructure outcomes: migration milestones hit, cloud costs controlled, application modernization completed. These are the visible metrics. The invisible metric (the one that determines whether the transformed environment is governable) is CMDB accuracy.
Every migration adds assets to the hybrid estate. Every modernization initiative changes the relationships between services. Every cloud expansion increases the rate of change that the discovery layer has to keep pace with. The CMDB earns its value after go-live, not at it: as the persistent operational infrastructure that makes everything built on top of it trustworthy.
Organizations that invest in high-frequency discovery and CMDB accuracy as part of the transformation program (not as a separate workstream to be addressed later) do not have to rebuild their governance foundation after the fact. The record layer grows with the infrastructure layer. The gap never opens.
Virima and Trusted Runtime Truth in hybrid environments
Virima provides IT discovery and CMDB automation designed for the hybrid estate described in this guide. Agentless IP-based scanning covers on-premises infrastructure. Native integrations with AWS and Azure APIs provide discovery-sourced cloud resource visibility. Optional Discovery Agents for Windows, macOS, and Linux maintain visibility for remote and endpoint assets outside the corporate network, running high-frequency discovery cycles that keep CI records current across every layer.
ViVID service maps provide live visualization of asset relationships and dependencies, overlaying open incidents, pending changes, and vulnerability data onto the dependency map so that change managers and incident responders work from current operational context, not historical diagrams. CMDB health dashboards track CI completeness, stale CI percentage, and data quality metrics, surfacing remediation workflows before data drift affects operational decisions.
The result is a CMDB that reflects the actual hybrid environment: not as it was last Tuesday, not as it was at the last quarterly audit, but as it is right now. That is Trusted Runtime Truth. And that is what makes the hybrid cloud transformation governable.
Ready to build Trusted Runtime Truth across your hybrid estate? Request a demo with Virima →





