
Root Cause Analysis in IT Incident Management: Why Configuration Data Is the Missing Layer
Most incident post-mortems start the same way: a war room, a ticket, and a team tracing connections that should have been documented but weren’t. The configuration data is six months stale. The service map was built manually and no one updated it after last quarter’s cloud migration. The question “what changed?” takes three hours to answer instead of three minutes. Root cause analysis in IT incident management depends on the accuracy of the data underneath it. When that data is stale, guesswork fills the gap — and incidents recur.
Root cause analysis (RCA) in IT incident management is the process of tracing an incident past its visible symptoms to the underlying configuration change, vulnerability, or dependency failure that caused it. Where incident management restores service, root cause analysis prevents recurrence. Most teams understand the distinction. The gap is data: RCA that runs on stale configuration records produces documentation, not answers.
Why Accurate Configuration Data Defines RCA Outcomes
IT incidents rarely have a single, isolated cause. A database slowdown links to a patch applied on Friday. An application outage traces back to a misconfigured load balancer that a discovery scan flagged three weeks earlier. The causal chain lives in the configuration data — but only if that data was captured accurately and updated frequently enough to reflect the actual state of the environment.
Teams that rely on manually maintained CMDBs face a compound problem: the data they need to run root cause analysis is often the data that drifts fastest. CI relationships, dependency paths, and ownership records go stale within weeks of a change. By the time an incident occurs, the CMDB shows the environment as it was, not as it is.
A discovery-sourced CMDB closes that gap. When configuration data is populated through regular discovery cycles rather than manual entry, incident responders can trust what they’re looking at. The service dependencies are accurate. The change history is current. The ownership records reflect the current state. That accuracy is the foundation any root cause analysis requires.
Learn what goes into building a CMDB that supports incident investigation — accuracy standards, relationship mapping, and the discovery architecture that keeps it current.
Root Cause Analysis vs. Problem Management in ITIL 4
Many teams treat incident management, root cause analysis, and problem management as interchangeable. ITIL 4 draws a clear line.
Incident management asks: “How do we restore service as quickly as possible?”
Problem management asks: “Why did this happen — and how do we stop it recurring?”
Root cause analysis is the investigation technique that problem management uses to answer the second question.
In practice, RCA runs after the immediate incident is contained. The incident ticket closes when service is restored. A problem record opens when the team commits to finding and eliminating the underlying cause. That problem record drives the root cause analysis — assigning ownership, tracking investigation steps, documenting workarounds, and ultimately linking to a change that implements the permanent fix.
This distinction matters because it defines where ITSM platforms end and configuration data begins. ServiceNow, Jira Service Management, Ivanti, and Halo manage the problem lifecycle. What they cannot do on their own is tell responders what the CI actually looked like, how it was connected, and what changed before the incident. That is the layer Virima provides. See how that connection works: how Virima connects ITSM incident management to CMDB.
There is also a proactive vs. reactive dimension to RCA. Reactive root cause analysis runs after an incident — tracing the cause of something that already happened. Proactive root cause analysis identifies potential failure conditions before they trigger an incident, using vulnerability data, configuration drift alerts, and change impact modeling. Virima’s ITIL problem management guide covers how to build both capabilities in practice.
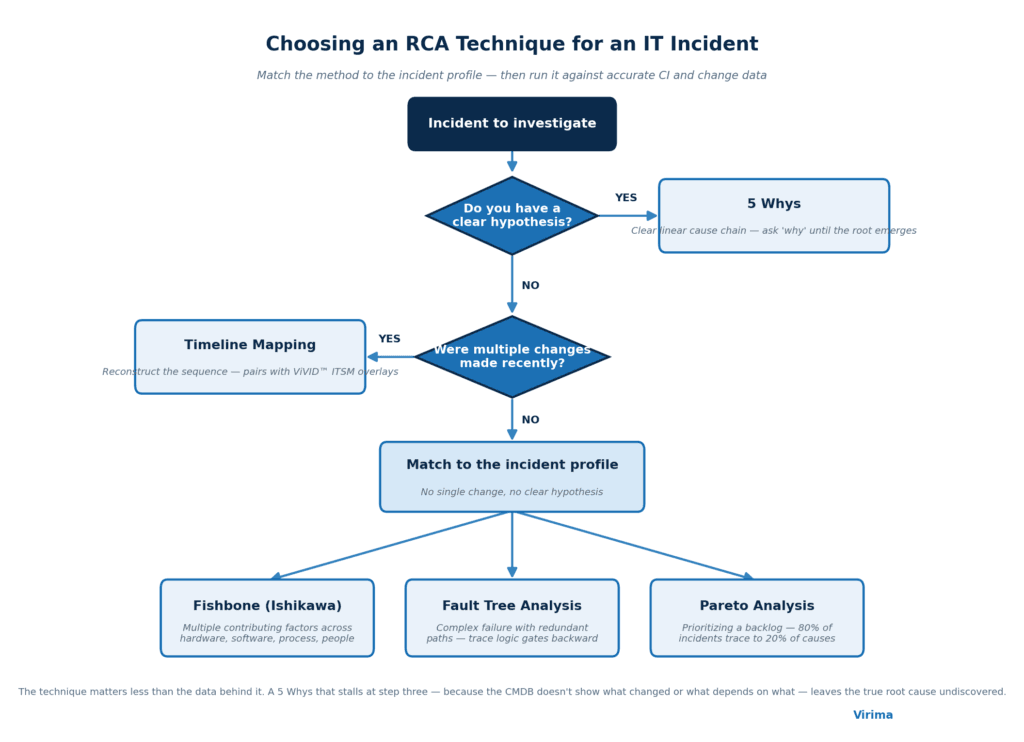
RCA Techniques for IT Incidents: Matching the Method to the Problem
No single root cause analysis technique fits every incident type. Choosing the wrong method wastes investigation time. The ITIL v3 Service Operation guidance maps scenarios to approaches:
| Incident Profile | Recommended Technique | When to Use It |
| Clear linear cause chain | 5 Whys | You have a hypothesis. Ask “why” five times; each answer becomes the next question. |
| Multiple contributing factors | Fishbone (Ishikawa) Diagram | Hardware, software, process, and people all appear to have contributed. Map all potential causes first. |
| Complex failure with redundant paths | Fault Tree Analysis | Start with the known failure and work backward through logic gates to all contributing conditions. |
| Prioritizing a backlog of problems | Pareto Analysis | 80% of incidents trace to 20% of root causes. Use Pareto to decide which problem to investigate first. |
| Multiple changes before the incident | Timeline Mapping | Reconstruct the sequence of events using change history. Pairs directly with ViVID™ ITSM overlays. |
The technique selection matters less than the data quality behind it. A 5 Whys analysis that runs out of information at step three — because the CMDB does not show what changed or what depends on what — leaves the actual root cause undiscovered.
How Virima Supports Root Cause Analysis Across the Incident Lifecycle
Virima adds three layers to root cause analysis that ITSM platforms cannot provide on their own: accurate, discovery-driven configuration data, visual service dependency mapping, and integrated vulnerability context.
Discovery-sourced CMDB: The accuracy foundation
Each root cause analysis depends on being able to answer three questions about the affected CI: what changed recently, what does it depend on, and who owns it. Virima’s discovery engine populates those answers through high-frequency discovery cycles across on-premises, AWS, and Azure environments — agentless or agent-based depending on the asset profile.
When a problem record opens in ServiceNow or Jira Service Management, the responder sees accurate dependency data, a complete change history, and current ownership — not what was documented last quarter. That accuracy significantly reduces MTTR and gives responders a foundation for investigation rather than an obstacle.
ViVID™ service maps: Seeing ‘what changed’ in seconds
ViVID™ service maps overlay open incidents, recent changes, pending changes, and NIST NVD vulnerabilities directly onto service dependency maps. When an incident lands, the responder sees not just the affected CI but the services it supports, the changes that touched it recently, and any open vulnerabilities that could have contributed.
The “what changed?” question — the starting point for most IT root cause analyses — becomes visual. A change applied the evening before an incident shows up on the map, connected to the affected service. That narrows the investigation before the first phone call.
ViVID™ also supports change management: before a fix is implemented, the team can visualize which other services the proposed change will affect. That prevents a root cause fix from generating a new incident on a connected service. See how that applies: Virima change impact analysis for ITSM.
[VISUAL: ViVID™ service map showing incident overlay on dependency map with change record and vulnerability flag visible on the same CI]
NIST NVD integration: Security-led root cause identification
Security vulnerabilities can contribute to a meaningful share of IT incidents in hybrid cloud environments, particularly those involving configuration exposure, unpatched services, or misconfigured access paths. Virima’s integration with the NIST National Vulnerability Database (NVD) surfaces known vulnerabilities in context on the service map — showing not just that a vulnerability exists, but which services and CIs it affects.
During root cause analysis, this data answers whether a known security flaw contributed to the incident. It also drives remediation prioritization: a patch for a vulnerability affecting a Tier 1 service moves to the front of the change queue, with a ViVID™ impact map showing exactly what the patch will touch before it is applied.
Accurate incident root cause analysis starts with data you can trust. Virima delivers Trusted Runtime Truth — explainable, confidence-scored configuration data you can trust across your CIs, dependencies, changes, and vulnerabilities at the moment of investigation.
The Root Cause Analysis Workflow with Virima
Root cause analysis does not happen in isolation — it runs inside the ITSM incident and problem management workflow. Here is how Virima supports each stage.
1. Detection and logging: An incident is detected and logged into the ITSM platform. The ticket captures the affected service, reporting user, and initial symptom. For known workarounds, service is restored here. For recurring or unexplained incidents, a problem record opens.
2. Impact assessment with ViVID™: ViVID™ overlays show the blast radius immediately — which services and downstream CIs are affected, what recent changes touched the environment, and what open vulnerabilities exist on the affected components. Responders see the full picture before the investigation begins.
3. Problem record and technique selection: The problem record assigns ownership and commits the team to finding the root cause. Based on the incident profile — single clear hypothesis, multiple contributing factors, or several recent changes — the team selects the appropriate RCA technique.
4. Investigation using discovery data: The investigation draws on Virima’s CMDB: change history, dependency paths, configuration drift records, and vulnerability exposure. The team runs their chosen RCA technique against accurate, discovery-driven data rather than reconstructing the environment from memory or stale documentation.
5. Resolution through change enablement: Once the root cause is identified, a change request is raised. Virima’s change impact analysis confirms which services the fix will affect before it is applied, preventing the resolution from creating a new incident. The change is approved, implemented, and logged.
6. Prevention and CMDB refresh: After the change is implemented, Virima’s next discovery cycle updates the CMDB to reflect the new configuration state. The corrected CI data feeds back into future investigations.
For service availability and outage prevention: how Virima supports service availability.
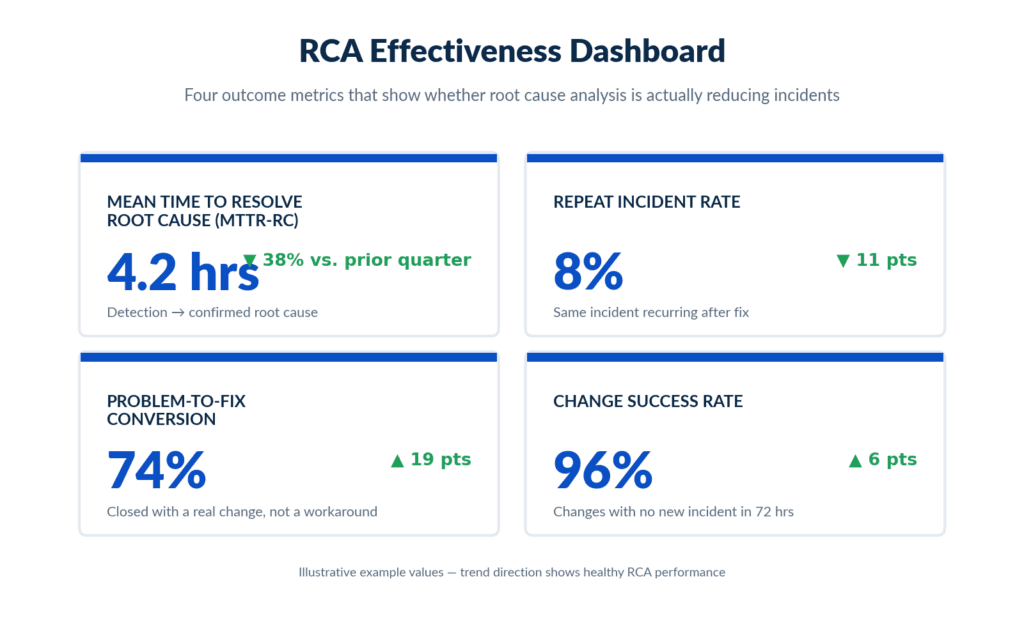
Measuring RCA Effectiveness: Four Metrics That Matter
Root cause analysis generates value in the operational data, not in the documentation. These four metrics indicate whether your RCA practice is actually reducing incidents.
Mean Time to Resolve Root Cause (MTTR-RC): Measures how long from incident detection to confirmed root cause identification. Declining MTTR-RC indicates improving data quality and tighter investigation workflows. It is the most direct signal that discovery-driven CMDB data is doing its job. As noted in ITSM.tools’ problem management framework, MTTR-RC is one of five outcome-based metrics organizations should track rather than activity counts.
Repeat incident rate: The clearest outcome metric. If root cause analysis is eliminating underlying causes, the same incident should not recur. A flat or rising repeat incident rate means root causes are being documented but not actually fixed — often because the original investigation ran on inaccurate data.
Problem-to-fix conversion rate: The percentage of closed problem records that resulted in an implemented change, not a permanent workaround. Low conversion suggests resourcing or prioritization gaps. Track this alongside MTTR-RC to distinguish between fast investigations that lead nowhere and thorough investigations that drive permanent fixes.
Change success rate: Track what percentage of changes do not generate a new incident within 72 hours. If changes regularly trigger secondary incidents, the pre-change impact analysis is missing something — usually accurate dependency data on what the changed CI supports.
From Incident Triage to Discovery-Driven Investigation
Incident root cause analysis has always been a data problem. Teams that struggle with recurring incidents rarely lack diagnostic skills — they lack accurate, timely configuration data to put those skills to work.
As IT environments add more services, more cloud infrastructure, and more automated workflows, the gap between what the CMDB shows and what the environment actually looks like widens. That gap is where repeat incidents live. It is also where the IT environment is heading: as AI-driven automation takes on more change and remediation work, any agent that acts on stale CI data risks making a logically sound decision with a factually wrong outcome. Accurate configuration data is what will keep those future decisions grounded.
Virima’s discovery-driven CMDB, ViVID™ service maps, and NIST NVD integration address that gap directly. They give incident responders and problem managers the Trusted Runtime Truth they need to run root cause analysis that leads somewhere — not just documentation of what went wrong, but a clear path to preventing it from happening again.
For teams running ServiceNow, Jira Service Management, Ivanti, Halo, or Xurrent, the investment does not require replacing the ITSM platform. It requires giving the platform accurate data to work with.
Request a demo to see how Virima supports faster incident root cause analysis in your ITSM environment.
Frequently Asked Questions
What is root cause analysis in IT incident management?
Root cause analysis (RCA) in IT incident management is the structured practice of identifying the underlying configuration change, vulnerability, or process failure responsible for an incident — not just the symptom that triggered the alert. It is the investigative step within problem management that prevents the same incident from recurring. Effective root cause analysis requires accurate CI data, mapped service dependencies, and complete change history. Without those three inputs, RCA produces documentation rather than durable fixes.
What is the difference between root cause analysis and problem management?
Problem management is the ITSM discipline; root cause analysis is the technique it uses. Problem management opens a problem record, assigns ownership, documents known errors and workarounds, and drives a permanent fix through change enablement. Root cause analysis is the investigation step within that lifecycle that determines why the incident occurred. In ITIL 4, incident management closes when service is restored — problem management closes when the root cause is eliminated and the fix is implemented.
How does a CMDB support root cause analysis?
A discovery-sourced CMDB supports root cause analysis by providing accurate configuration item records, dependency relationships, and change history at the moment an incident is investigated. When CI data reflects the actual state of the environment — populated through regular discovery cycles rather than manual entry — teams can trace incident causes to specific changes, misconfigurations, or vulnerable components in minutes. See what goes into building a CMDB that supports incident investigation.
What RCA technique works best for complex IT incidents?
For complex IT incidents with multiple potential causes, Fault Tree Analysis works well because it starts with the known failure and traces backward through all possible contributing paths. When several changes occurred close together before an incident, Timeline Mapping paired with ITSM overlay data — showing changes on a ViVID™ service map — narrows the investigation before the first diagnostic command runs. The key is matching the technique to the incident profile and having accurate CI and change data to fuel the analysis.
How does Virima integrate with ServiceNow or Jira Service Management for root cause analysis?
Virima integrates with ServiceNow, Jira Service Management, Ivanti, Halo, and Xurrent by enriching incident and problem records with discovery-driven CI data, service dependency maps, and change history. When a problem record opens in any of these platforms, responders can access ViVID™ service maps showing affected services, recent changes, and NIST NVD vulnerability overlays — without leaving the ITSM workflow. Explore how Virima connects ITSM incident management to CMDB.
Request a demo and see how discovery-driven configuration data accelerates root cause analysis in your ITSM environment.





