CMDB Readiness for Agentic AI: The 7 Discovery-Sourced Data Requirements
AI agents are moving from demo environments into production IT operations. They are being asked to triage incidents, assess change impact, flag compliance gaps, and trigger remediation without waiting for a human to assemble context first. That shift puts new pressure on one source of truth: your CMDB.
According to Gartner, at least 15% of day-to-day work decisions will be made autonomously through agentic AI by 2028, up from near zero in 2024 (Gartner). The IT teams getting ahead of that shift are not only deploying AI tools. They are auditing whether their operational data can support autonomous decision-making at all.
Most cannot pass that audit. The gap is almost never the AI model. It is the CMDB.
An AI agent that queries your CMDB expects to find trusted runtime truth: what actually exists, how assets are connected, what changed, what is likely to break, and who owns it. If the data is incomplete, stale, or disconnected from real discovery, agents act on fiction.
This guide defines the 7 data requirements your CMDB must meet before AI agents can operate safely in your environment, and explains why each one should be grounded in discovery data rather than manual entry.
Why Discovery-Sourced Data Is the Baseline
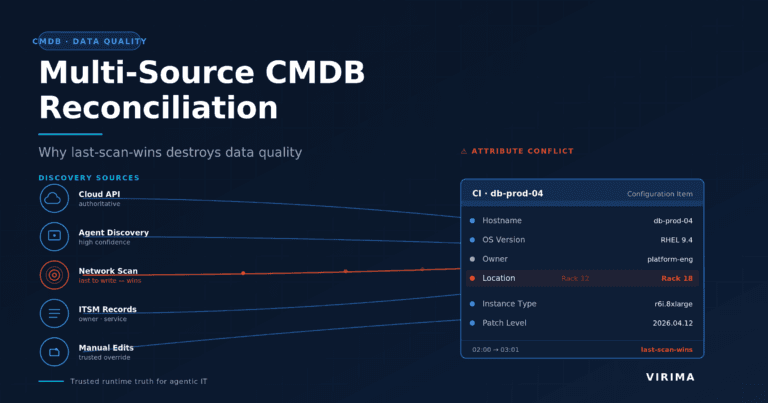
One framing principle matters before we walk through the seven requirements. CMDB data that was manually entered, imported from spreadsheets, or never validated against actual network state is a weak foundation for agentic operations.
Data built from discovery means the CI records in your CMDB were populated or validated by actual IT discovery, including agent-based scans, agentless probes, network device sweeps, and cloud API queries. That origin matters because it gives you strong confidence that what sits in the database reflects what actually exists on the network.
Each of the seven requirements below assumes this as the baseline. CMDB populations built primarily from manual input will struggle to meet most of them.
Requirement 1: Complete Multi-Source CI Inventory
An AI agent cannot reason about gaps it cannot see. If a meaningful share of your endpoints are missing from the CMDB, or your cloud workloads are not inventoried alongside on-premises infrastructure, any agent working on that data has an incomplete picture.
Completeness requires coverage across every discovery method: agent-based discovery for deep endpoint data, agentless scanning for devices that cannot run agents, network device discovery for switches and firewalls, cloud asset discovery across AWS and Azure, and virtual machine discovery across VMware and Hyper-V environments. Virima runs high-frequency discovery cycles across all of these methods and feeds the results into a single CI record per asset, reconciled across sources with conflicts resolved by a defined authority rule rather than a last-writer-wins model.
Readiness check: What percentage of your CIs were built from discovery versus manual entry? Is your cloud inventory kept current alongside on-premises assets?
Requirement 2: Multi-Source Reconciliation Into a Single Authoritative Record
A CMDB with multiple records for the same server (one from SCCM, one from Intune, one from an agent scan) is not usable for AI decision-making. Agents need to query one record and get one answer.
Multi-source reconciliation means taking input from multiple discovery sources and producing a single, conflict-resolved CI record with clear source attribution at the attribute level. If the agent queries a CI’s patch level, it should receive one value, from one defined source.
Virima applies attribute-level authority rules to resolve conflicting CI data. A discovery scan can win for hardware specifications while Intune wins for compliance state. The result is a single record the agent can trust without querying multiple systems to reconcile the answer. For teams running ServiceNow, this is the same principle behind enriching an existing CMDB without adding duplicates and noise.
Readiness check: Do you know which source wins for each attribute type in your CMDB today? Or are agents querying duplicate records and working from conflicting data?
Requirement 3: Dependency Relationships and Impact Visibility
An AI agent that can identify a failing server but cannot trace which services depend on it is not equipped to make a safe decision. It could trigger a restart at exactly the wrong moment and take down a production service in the process.
Impact visibility requires that every CI in your CMDB has populated relationship fields: what it depends on, what depends on it, and which business services it supports. That relationship data should be built from discovery and structured service definitions, not from manual mapping that goes stale the moment someone deploys a new workload.
Virima’s ViVID™ Service Mapping builds dynamic application-to-infrastructure dependency maps once service definitions are provided. With the composition of each service defined, Virima builds and maintains the dependency structure, giving agents the context to assess downstream impact before taking action. For the underlying concepts, see how a reliable CMDB maps relationships.
Readiness check: Can your CMDB answer “if this CI fails, what breaks?” in under 30 seconds, without a human tracing the map manually?
Requirement 4: Ownership and Accountability Metadata
When an agent needs to escalate, because the data is ambiguous, the risk exceeds a threshold, or a policy flag is triggered, it needs to know who owns the asset. Not the department. The specific person or functional role responsible for that CI.
Missing ownership data forces agents into one of two failure modes: halting on every ambiguous decision until a human intervenes, or acting without accountability context and creating a governance gap that is difficult to explain after the fact.
Virima’s CMDB tracks ownership at the CI level. That data feeds directly into the escalation paths that agentic IT frameworks depend on to hand off to the right human at the right time.
Readiness check: What percentage of your CIs have a named owner field populated today? Run that query. The result will tell you more about your real AI readiness than almost any other single metric.
Requirement 5: Change History and Configuration Drift Records
Agentic AI needs to reason about change, not only about current state. If a configuration drifted three weeks ago and the CMDB only shows what the CI looks like today, the agent is working without the context it needs to assess risk accurately.
Change history means every CI record includes a log of what changed, when, by what process, and from what prior state. That log is the foundation for root cause analysis, drift detection, and for agents that need to distinguish “this is how it is configured” from “this is how it is supposed to be configured.”
Virima’s audit record and history logging captures changes to CI records, giving agents the backward-looking context they need to identify when a configuration deviated from baseline and why.
Readiness check: Can you query a CI’s full change history for the last 90 days, including the attribute values before and after each change?
Requirement 6: Policy and Compliance Flags
Not all assets are eligible for autonomous action. End-of-life hardware should not receive new workloads. Assets under active vulnerability investigation should not be included in remediation scripts. CIs flagged for compliance review should trigger approval workflows, not autonomous decisions.
Policy and compliance metadata at the CI level is what separates an agent that acts within safe boundaries from one that applies changes to assets that should never have been touched.
Virima’s ITAM capabilities track end-of-life and end-of-support dates, license compliance state, and contract status at the asset level. That data flows into the policy layer agents need to make bounded, defensible decisions.
Readiness check: Does your CMDB surface EOL status, compliance flags, and vulnerability state per CI? Or does an agent have to query multiple separate systems to assemble that picture?
Requirement 7: ITSM Integration with Bi-Directional Sync
The final requirement is about data flow, not data content. AI agents acting inside ITSM platforms, including ServiceNow, Ivanti, Jira Service Management, and xurrent, need the CMDB data inside those platforms to match the discovery-sourced ground truth.
One-way syncs, or batch syncs that run on a monthly cycle, leave agents working with context that is weeks behind reality. Bi-directional sync means changes in either system are reflected in both, and high-frequency discovery cycles keep the CMDB current between sync events.
Virima integrates via bi-directional CMDB sync with popular ITSM platforms including ServiceNow, Ivanti, Halo, Jira Service Management, and Xurrent, so the data your agents access inside your ITSM platform reflects what Virima discovered on the network.
Readiness check: When was the last time a CI update in your ITSM platform was validated against actual discovery data for accuracy?
The CMDB Readiness Checklist for Agentic AI
Use this as a starting point for your own audit. Each row maps to one of the seven requirements above.
| # | Requirement | Key Readiness Question |
| 1 | Multi-source CI completeness | Are all asset types inventoried: endpoints, cloud, network, VMs? |
| 2 | Single authoritative record per CI | Is conflicting data reconciled with attribute-level authority rules? |
| 3 | Dependency relationships and impact | Can every CI answer “what breaks if this fails?” |
| 4 | Ownership and accountability metadata | Does every CI have a named owner for agent escalation paths? |
| 5 | Change history and drift records | Is 90 days of change history queryable per CI? |
| 6 | Policy and compliance flags | Are EOL, compliance, and vulnerability states surfaced per CI? |
| 7 | ITSM bi-directional sync fidelity | Does your ITSM data reflect high-frequency discovery results? |
What This Means for Your CMDB Strategy
Meeting all seven requirements is not a one-time project. It is an ongoing operational commitment to keeping CMDB data accurate, fresh, and complete, starting from discovery rather than from manual entry or periodic imports.
The IT teams that build this foundation treat CMDB management as an infrastructure discipline. They run high-frequency discovery cycles. They enforce ownership at the CI level. They sync bi-directionally with ITSM platforms. And they build agentic AI on top of that foundation, rather than deploying agents on a CMDB that was never designed to support autonomous operations.
| Walk through your current CMDB data state with our team and see where you stand against these seven requirements. Request a demo. |