
Agentless Asset Discovery: How It Works and How Virima Simplifies It
Agentless discovery is a way to find and list IT assets across a network without installing software agents on each device. Using protocols such as SNMP, WMI, SSH, and REST APIs, it queries endpoints remotely to collect hardware, software, and setup data, and it gives broad visibility with no performance hit on the systems it scans.
In one widely cited study, 79% of organizations admitted they lack full visibility into their IT assets (Axonius/ESG, 2021), and that gap usually starts here: an approach that asks you to install and maintain agents on every endpoint simply does not scale.
This article explains how the method works, how it differs from agent-based approaches, when to use each, and how Virima’s agentless probes feed accurate CI data directly into your CMDB.
What is agentless discovery?
Agentless discovery finds the assets on your network by querying devices remotely, rather than running software on each one. It uses credential-based and credential-free methods to collect CI attributes: hostname, operating system, hardware specs, serial number, installed software, network relationships, and more.
Because nothing sits on the endpoint, the scanner works on nearly any reachable device. As a result, you skip compatibility testing, rollout planning, and endpoint permission work.
How agentless discovery works, step by step
A typical agentless scan runs in four steps:
- First, you define a subnet range or IP block for the discovery tool to scan.
- Next, the tool connects to each device using a configured set of credentials and protocols.
- Then, on a successful connection, it collects CI attributes and relationship data from the device.
- Finally, the tool normalizes that data and pushes it into your CMDB, creating or updating CI records automatically.
Which protocols agentless discovery uses
- SNMP (Simple Network Management Protocol) — for network infrastructure: routers, switches, printers, IoT devices
- WMI / WinRM (Windows Management Instrumentation) — for Windows servers and workstations
- SSH (Secure Shell) — for Linux, Unix, and macOS endpoints
- REST APIs — for cloud workloads in AWS, Azure, and similar platforms
- Passive fingerprinting / credential-free scanning — spots devices from network traffic and response signatures, without any credentials
Agentless vs. agent-based discovery
Agent-based discovery installs lightweight software on each device to report configuration data back to a central server. This gives deep telemetry, but it requires deployment across every endpoint.
Agentless discovery, in contrast, scans the network with credentials and protocols to collect the same core asset data without any software installation. Therefore, teams prefer the agentless approach for broad initial coverage, while they prefer agent-based discovery where off-network visibility or strict security isolation matters.
| Agentless discovery | Agent-based discovery | |
| Deployment | No software on endpoints; configure subnet + credentials | Install and maintain an agent on every device |
| Time to first inventory | Single scan pass | Weeks of rollout and validation |
| Endpoint performance impact | None (remote query) | Local CPU/memory overhead |
| Best for | Servers, cloud, network gear, OT/IoT, initial CMDB population | Laptops, remote/VPN endpoints, deep usage telemetry |
| Off-network visibility | Limited to discovery windows | Continuous, including off-network |
| Maintenance burden | Centralized | Per-endpoint updates and compatibility testing |
Still, neither approach covers everything on its own. Agentless works best for broad initial coverage, cloud workloads, and infrastructure that cannot support agents. Agent-based, meanwhile, works best for laptops, remote workers, and VPN-connected endpoints that often leave the network. Because of this, a combined approach uses agentless for the foundation and agents for depth where you need it, which gives the widest coverage.
Benefits of agentless discovery
Fast time to visibility
The agentless approach needs no endpoint prep. You configure a subnet range, set credentials, and the discovery cycle runs. In environments with hundreds or thousands of devices, the first cycle builds a full CI inventory in a single pass. As a result, you avoid the weeks teams normally spend rolling out and validating agents across the estate.
No endpoint performance impact
Because the scanner queries devices remotely rather than running locally, monitored endpoints carry no CPU or memory overhead. This matters in production, where extra software on critical servers adds risk.
Lower security footprint
Every agent on an endpoint is a potential attack surface. Agentless scanning removes that surface, since it relies on standard protocols that most organizations already allow across their network segments. In short, there is nothing to exploit on the endpoint, because there is nothing installed there.
Lower total cost of ownership
Agent deployment means an initial rollout, ongoing updates, and compatibility testing against every OS version and application stack. The agentless model centralizes all of that. Therefore, it cuts the long-term maintenance load on IT teams.
Discovers assets you did not know you had
Agentless discovery suits environments where agent deployment is impractical at scale, such as large server estates, cloud workloads, OT/IoT devices, or any network where keeping software on every endpoint costs too much. It also makes a strong first step for a CMDB population project, because it needs no prior asset inventory to run and surfaces unknown devices that agent-based approaches miss.
In other words, a network scan does not need a prior asset list. Instead, it surfaces the devices that respond, including endpoints nobody ever inventoried, unauthorized devices, and shadow IT that agent-based tools miss because nobody knew to install an agent there.
When to use agentless discovery
When agentless alone is sufficient
For most data center and cloud-first environments, this approach covers everything in scope: servers, virtual machines, network infrastructure, storage, printers, cloud instances, and OT/IoT devices. So if your devices sit on-network and stay reachable during discovery windows, a network scan gives you a current, accurate CI inventory without extra tools.
In practice, it is the right choice when:
- You need an initial CMDB population and no prior inventory exists
- Your environment includes OT or IoT devices where you cannot install an agent
- Security policy blocks third-party software on servers
- You are onboarding a newly acquired environment and need fast visibility
When to supplement with agent-based discovery
That said, consider adding agents when a large share of your fleet consists of laptops or mobile endpoints that often go off-network, when you need usage-level telemetry (software usage, active processes) beyond what network scanning retrieves, or when the scanner cannot reach security-isolated subnets. In these cases, agentless discovery handles the bulk of coverage, while agents fill the gaps for hard-to-reach endpoints.
Agentless discovery across cloud, OT, and IoT
Modern IT environments reach well beyond the data center. A single enterprise network often spans cloud workloads, on-premises servers, operational technology (OT) devices on the factory floor, and IoT sensors across physical facilities. The agentless approach, however, handles each of these differently.
Cloud: API-based discovery connects directly to AWS, Azure, and similar platforms to list instances, containers, and managed services. It needs no network-level access to the cloud, because the provider’s API surface does the work.
OT and industrial devices: SNMP and passive fingerprinting cover most OT assets, including PLCs, SCADA systems, and industrial sensors. Because these devices usually cannot support an agent, a network-based scan becomes the primary viable method for this asset class.
IoT endpoints: Credential-free fingerprinting spots IoT devices from their network response signatures, even when a device lacks the login methods that SNMP or SSH-based scanning needs.
Without coverage of these asset types, they stay invisible in your CMDB. As a result, you get security blind spots and incomplete service maps that do not reflect the full scope of your environment.
Agentless discovery as the foundation for agentic IT operations
AI agents that handle IT operations — incident triage, change impact analysis, access governance — act on CMDB data. So if that data is stale or incomplete, the agent bases its decisions on a false picture of the environment.
According to Gartner, AI agents will make at least 15% of day-to-day work decisions autonomously by 2028, up from none in 2024 (Gartner, 2025). Those agents need configuration data that reflects what actually exists, not a snapshot from the last manual update.
Agentless discovery, running on high-frequency cycles, keeps CI records current. As a result, automated workflows and agentic systems act on accurate, discovery-sourced ground truth rather than outdated manual entries. For example, when an AI agent calculates blast radius before a change, routes an incident to the right team, or validates an access request, it is only as correct as the CMDB data it reads. Stale CIs, therefore, do more than create operational blind spots — they feed incorrect inputs into decisions that downstream teams will trust without question.
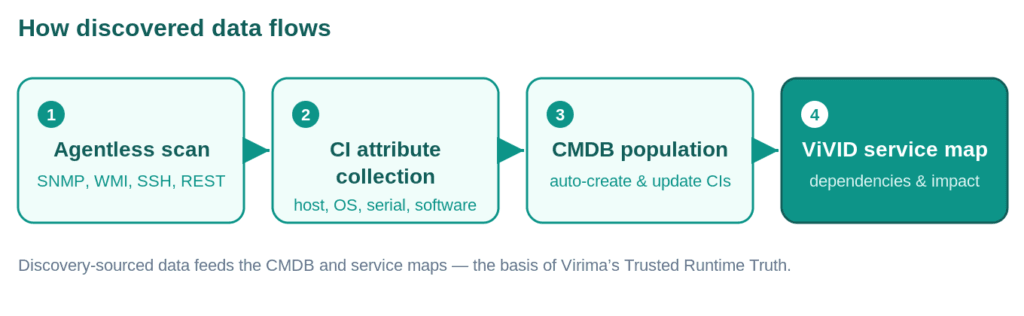
Discovered CI data flows from Virima’s agentless probes into your CMDB, which then drives ViVID service maps that show what depends on what, who owns it, and what will break if it changes. That pipeline — from discovery to CMDB to service map to governed action — is what Virima calls Trusted Runtime Truth: discovery-sourced, explainable, and governed.
Explore Virima’s Trusted Runtime Truth approach →
How Virima’s agentless discovery works
Virima’s IT discovery is IP-based and subnet-targeted. You select the network ranges to scan, set credentials, and pick from a library of out-of-the-box discovery probes, each tuned for a specific device class or protocol. In addition, a custom probe generator lets you extend coverage to non-standard device types without scripting from scratch.
Here are the key characteristics of Virima’s agentless discovery:
- Configurable discovery cycles — high-frequency cycles run on your set cadence, so no one has to start them by hand
- Intelligent scan throttling — the scanner spreads query load to avoid flooding network segments during peak hours
- Scan result transparency — every report shows successes, failures, and failure reasons by device, so you know exactly what the scan found and what it did not
- Coverage across all environment types — servers, workstations, virtual machines, network gear, printers, cloud instances, OT devices, and IoT endpoints
- Deep CI attributes — model, serial number, BIOS, OS version, installed software, hostname, network relationships, and more
All discovered data flows directly into your CMDB, where it populates CI records and updates relationships. Then, as CIs change, the data refreshes on the next cycle and keeps your service maps and IT asset management records accurate.
Virima also integrates bidirectionally with ServiceNow, Jira Service Management, Ivanti, Xurrent, Hornbill, and Halo. So discovery-sourced CI data flows into the ITSM tools your team already uses, without manual export or cleanup.
See agentless vs. agent-based side by side — download the discovery coverage checklist →
Frequently asked questions
What is agentless discovery in IT?
Agentless discovery identifies and catalogs IT assets by querying devices remotely over the network, using protocols such as SNMP, WMI, SSH, and REST APIs. The scanner installs no software on monitored devices. Instead, it collects hardware, software, and configuration data from each responding endpoint and delivers it to a central management system or CMDB.
What is the difference between agentless and agent-based IT discovery?
Agent-based discovery installs a software agent on each device to collect and report data locally. Agentless discovery, by contrast, queries devices remotely without installing any software. So the agentless method gives you faster deployment and lower upkeep, while agent-based gives you deeper telemetry and tracks endpoints that leave the corporate network. In practice, many organizations use both.
Can agentless discovery populate a CMDB automatically?
Yes. Agentless tools collect CI attributes — hostname, OS, serial number, relationships, installed software — during each cycle and then push that data directly into the CMDB. Virima’s agentless probes feed discovered CIs into the CMDB through high-frequency cycles, which produce service maps that reflect the current state of the environment.
Does agentless discovery work for cloud and OT/IoT assets?
Yes. REST API connections discover cloud assets on AWS, Azure, and similar platforms. Meanwhile, SNMP and credential-free fingerprinting reach OT and IoT devices, and neither needs an agent. This makes the agentless method the primary option for asset types where agent deployment is impractical.
When should agentless discovery be supplemented with agent-based discovery?
Consider adding agents for laptops and mobile devices that often go off-network, for endpoints behind strict security isolation, or for cases where you need software usage





